
 [책] 자연어 처리 딥러닝 캠프
[책] 자연어 처리 딥러닝 캠프
딥러닝 기반의 자연어 처리를 기초부터 심화까지 두루 다루는 책이 한빛미디어에서 출간되었습니다. 바로 자연어 처리 딥러닝 캠프인데요, 이 책의 모든 예제는 PyTorch 1.0을 기반으로 다루고 있으며 딥러닝의 기초 서적이 아니기 때문에 목적/손실 함수, 선형/로지스틱 회귀, 그래디언트 디센트 정도는 이미 숙지하고 있다는 가정하에 내용을 진행합니다. 책의 표지에서부터 PyTorch의 기운이 느껴집니다. 책의 모든 페이지가 컬러로 되어 있어서 꽤 세련된 느낌을 주고 패스트캠퍼스에서 진행한 강의가 바탕이 되어서인지 내용 구성이 좋아서 훌훌 잘 읽힙니다. 매 단원이 끝날때마다 딥러닝의 대가들(제프리 힌튼, 클로드 셰넌, 얀 르쿤 등)이 스케치 이미지로 등장하는데 누가 등장할지 궁금해서 더 빨리 읽게 되는것 같기..
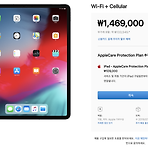 아이패드 구매 고민...
아이패드 구매 고민...
요즘 태블릿 구입을 고민하고 있는데 역시 큰 범주 안에서는 애플 제품이고 상세로 들어가면 프로 혹은 미니로 나눌 수 있겠습니다. 아이폰 X 이후로 홈버튼이 사라진 걸 보면 이제서 홈버튼이 있는 건 디자인적으로 별로 좋아 보이지 않고... 그런 이유로 프로에 마음이 많이 가는 것은 사실이지만 현실적으로 가격이 너무 버겁네요. 과연 그만한 값어치를 할 수 있는 장난감인지 장담도 못하겠고요. 왜냐면 일단 태블릿을 사용해본 경험이 없기 때문입니다. 미니는 프로의 절반정도 가격으로 구매할 수 있는데 또 세부적으로 들어가면 wifi 모델을 살지 Cellular를 사야 할 지 고민이네요. 주변에 보면 대부분 wifi 모델을 구매하면 후회한다고 하는데... 이것도 가격이 그리 호락호락한 편은 아니네요. 과연 잘 갖고 ..
 매직마우스 가속도 설정 끄기
매직마우스 가속도 설정 끄기
매직마우스를 사용하다보면 마우스 가속이 생각보다 편한데 가끔은 이 설정이 필요 없을때가 있습니다. 아니, 오히려 없어야 하는 상황이 말이 맞겠네요. 보통은 게임을 할 때 그렇겠죠? 이 설정을 끄려고 마우스 설정을 살펴보면 관련된 내용이 없다는 것을 확인 할 수 있습니다. 하지만 터미널에서는 defaults 명령어를 마우스 가속도를 설정할 수 있습니다. 일단 현재 설정되어 있는 값을 읽어옵니다. 제 경우에는 1.5로 설정이 되어 있네요. defaults read .GlobalPreferences com.apple.mouse.scaling 이 설정을 끄려면 -1로 write 해주면 됩니다. 아래처럼 말이죠. defaults write .GlobalPreferences com.apple.mouse.scalin..
 [책] Python for Data Analysis
[책] Python for Data Analysis
파이썬과 머신러닝에 한참 빠져있다보니 여러 오픈소스를 살펴볼 수 있었는데요. 간혹 난해한 코드를 만나는 경우가 분명 있었습니다. 어떤 의미로 사용된 코드인지 이해하기 위해서 별도의 의사코드를 작성해서 진행을 해보기도 하고, 특히 matplotlib같은 경우에는 매번 당장 사용할 때가 아니면 그 사용법을 익혀두기 어려웠습니다. 그러던중 좋은 기회로 한빛미디어에서 출간된 Python for Data Analysis를 만나게 되었습니다. 1판이 무려 만 오천여부가 팔렸다고 하니 이미 그 수치에서 이 책은 신뢰할 수 있겠습니다. 책의 초판은 2012년에 출간되었고 당시에는 파이썬의 열풍이 지금처럼 대단하지 않았었죠. 이미 상당한 시간이 흘러 머신러닝과 빅데이터에 힘입어 Python은 이제 대세 language로..
 Audacity는 이미 실행 중입니다.
Audacity는 이미 실행 중입니다.
Ubuntu 16.04에서 Audacity를 사용하던 도중에 어떤 이유로 시스템을 재부팅 했는데 (OS crash로 인해), 부팅이 된 후로는 Audacity가 실행이 안됐습니다. 실행시켜보면 아래와 같은 팝업만 노출이 되었구요. 아마도 프로그램이 실행될 때 대부분의 애플리케이션이 그러듯이 pid 파일을 저장해둘 것 이라고 생각했는데요. 관련해서 보통의 애플리케이션은 pid를 /var/run/ 디렉터리 밑에 저장하도록 처리를 합니다. 하지만 Audacity 관련해서는 찾을 수가 없었습니다. 조금 더 찾아보니 아래 경로에 lock 파일이 있었네요. /var/tmp/audacity-{USER}/audacity-lock-{USER} 해당 파일을 삭제하고 Audacity가 정상적으로 동작되는 것을 확인했습니다...
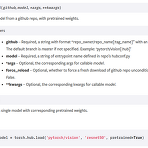 PyTorch Hub 톺아보기
PyTorch Hub 톺아보기
앞선 글에서 PyTorch Hub를 맛보고자 Load tacotron2+waveglow from PyTorch Hub 를 진행해봤습니다. 이번 글에서는 PyTorch Hub가 어떤 원리로 어떻게 사용되는 것인지 살펴보려고 합니다. 모든 내용을 살펴본 이후에는 우리의 커스텀 모델을 등록하는 것으로 글을 마무리 합니다. torch.hub.load() 자, 이전에 작성했던 코드에서부터 출발 해볼까요? # contents of waveglow.py import torch waveglow = torch.hub.load('nvidia/DeepLearningExamples', 'nvidia_waveglow') torch를 import하고 torch.hub.load() 함수를 통해 미리 학습된 모델을 불러왔습니다. 이..
 Load tacotron2+waveglow from PyTorch Hub
Load tacotron2+waveglow from PyTorch Hub
PyTorch Hub의 기세가 무섭습니다. 코드 구현체를 찾으려면 GitHub을 기웃거리면 되고 컨테이너를 찾으려면 Docker Hub로 가면 되듯이 얼마후면 딥러닝 모델 구현체를 찾기 위해서는 PyTorch Hub를 찾는 날이 올지도 모르겠습니다. 유명한 딥러닝 모델의 구현체들이 아래처럼 속속 등록되고 있는데요, 그중에 유독 눈에 띈 것은 Filter를 audio로 지정했을 때 나오는 Nvidia에서 구현한 Tacotron2, WaveGlow였습니다. 요즘 관심있게 보고 있던 모델이었기 때문에 PyTorch Hub와 함께 묶어서 살펴보기 좋겠다는 생각이 들어서 아래 링크를 참고해서 테스트를 진행해봤습니다. https://pytorch.org/hub/nvidia_deeplearningexamples_wa..
 Docker 컨테이너 안에 jupyter 접속하기
Docker 컨테이너 안에 jupyter 접속하기
여기 블로그 글을 RSS 받으시는 분들은 아시겠지만 저는 도커 환경을 꽤 좋아합니다. 일단 1) PC를 군더더기 없이 깔끔하게 사용할 수 있는 장점이 있고 2) 정리할때도 깔끔하게 할 수 있습니다. 3) 나중에 다른 시스템으로 옮길 때 호환성은 이루말 할수 없습니다. 아무튼, 이런 장점들 때문에 웬만하면 모든 개발을 도커에서 진행하고 있는데 아래와 같은 상황을 마주했습니다. 한참 딥러닝 모델을 개발하고, 이를 jupyter notebook으로 inference등의 테스트를 진행하려고 보니, Host 머신에서 jupyter의 포트로 접속 할 수가 없지 않겠습니까? Host에서 컨테이너 내부의 포트로 접속하려면 PNAT나 Proxy를 사용해야 하는데 이런것들은 처음 컨테이너를 생성할 때 지정을 해줘야 하는 ..
librosa를 이용해서 load, write 하는 방법은 아래처럼 간단합니다. from librosa.core import load from librosa.output import write_wav y, sr = load('/tmp/test.wav', sr=44100) write_wav('/tmp/new.wav', y, sr) 그런데 write_wav() 하는 과정에서 에러가 발생하는 경우가 있는데요. librosa.util.exceptions.ParameterError: data must be floating-point 원본 파일에 따라 에러가 발생되는 경우가 있는 것 같습니다. 일단 상세한 원인은 librosa쪽 코드를 열어봐야겠지만 가장 간단한 해결방법은 librosa를 다시 설치하는 겁니다. 기..
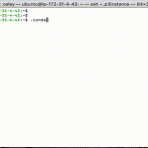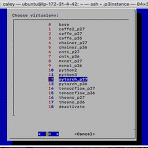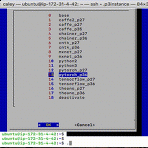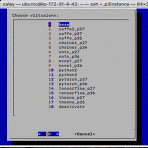 conda tab completion (자동완성) 만들기
conda tab completion (자동완성) 만들기
conda를 사용하면서 activate와 deactivate를 타이핑하는 것이 왜 이리 힘들던지, 그리고 환경을 이동하는 것이 어찌나 불편했는지 모릅니다. 그래서 dialog를 이용해서 아래와 같은 툴을 만들어서 사용하기도 했습니다. 예를 들어 터미널에서. conda라는 명령어를 타이핑하면 바로 위의 dialog가 나옵니다. 그리고 환경을 선택해서 사용했었네요. 소스코드는 아래 링크에서 확인하실 수 있습니다. https://github.com/jybaek/conda_connector 주로 이런 방식으로 사용해오다가 다른 git, docker와 같은 일반적인 명령어들처럼 tab을 이용해서 자동 완성하는 게 더 고급져 보이지 않을까 하는 생각을 하게 됩니다. 그래서 bash_completion을 만들게 되었..
 Jekyll 블로그 docker로 한방에 올리기
Jekyll 블로그 docker로 한방에 올리기
GitHub을 통해 호스팅이 가능해지면서 Jekyll 블로그가 선풍적인 인기인데요, 이 대열에는 제가 활동하고 있는 Google Cloud Platform 사용자 그룹의 홈페이지도 합류해있습니다. 페이지를 운영하면서 소스코드를 수정 할 때면 바로바로 결과물을 확인 할 수 없었기 때문에 자질구레한 커밋들이 너무 많이 남게 되었는데요. 사실 로컬에 Jekyll 환경을 구축하고 결과물을 확인하면서 개발하면 이런 불상사를 막을 수 있습니다만, 그 환경을 구축하면 또 뭔가 찝찝한 설치 파일들이 OS 구석구석에 설치되겠죠. 아래처럼 gem이 기본적으로 설치되어 있어야 하고 gem으로 bundler, jekyll 설치해야 합니다. 그리고 끝으로 번들을 이용해서 서버를 올리는 구성인거죠. 뭐 설치되는게 이정도면 양반이..
 [CVE-2019-12735] Vim 취약점 발견
[CVE-2019-12735] Vim 취약점 발견
https://github.com/numirias/security/blob/master/doc/2019-06-04_ace-vim-neovim.md 평소 vim을 즐겨 쓰고 있는데 회사 동료가 vim 패치를 하셔야 하지 않냐며 링크를 던져주셨습니다. 링크에 취약점 내용을 살펴보니 1) 공격자는 nc(netcat)을 통해 포트를 열고 있고 2) 공격자가 배포한 특수 파일을 보통의 사람이 vim으로 열었을 때 3) 파일에 감춰져있는 코드가 동작. nc로 shell을 실행시켜 공격자에게 연결해주는 방식이네요. 셸을 통째로 열어주는 것이기 때문에 상당히 위험한 취약점이지만 이 모든 게 성립하려면 1) 사용자가 계속 특수 파일을 열고 있어야 하고(닫으면 공격자와 연결된 세션이 종료됨), 2) 사용자의 OS에 설치된..
 다시쓰는 Flask unittest (하편)
다시쓰는 Flask unittest (하편)
이전 편 : 다시쓰는 Flask unittest (상편) 앞서 우리는 Flask의 기본 예제코드를 pytest를 통해 테스트해봤습니다. 몇 몇 분들은 아마 눈치를 채셨을지 모르겠지만 사실 앞에서 테스트한 내용은 함수 단위의 테스트지 실제 Flask 서버와 무관합니다. /hello, /world 와 같은 API를 테스트한다고는 했지만 사실상 hello(), world() 함수를 호출하고 끝냈으니까요. 이번에는 조금 더 현실적인 Flask 코드를 놓고 unittest를 진행하는 방법에 대해서 알아보도록 하겠습니다. 일단 아래처럼 미리 준비된 코드를 가져와봤습니다. #!/usr/bin/env python # coding=utf8 # content of my_flask.py # Restful API from f..
 다시쓰는 Flask unittest (상편)
다시쓰는 Flask unittest (상편)
우리가 개발한 프로그램을 테스트하는 방법론이 여러가지 나오고 있는데 이번에는 그 기본이 되는 unittest를 flask와 연계해서 알아보고자 합니다. 인터넷에 flask와 unittest로 검색해보면 Flask 공식 홈페이지를 포함해서 여러자료가 리스트 되지만 대부분 공식 홈페이지의 예제를 그대로 참고한 것으로 이해하기에 난해한 부분이 있습니다. 그래서 굳이 넘쳐나는 자료들 속에 다시 키보드를 잡아들었습니다. 아무튼 이번 글이 누군가에게 현실적인 도움이 되기를 바랍니다. Flask 코드 작성 우선 unittest를 위해 아래와 같은 코드를 작성해보도록 합시다. # contents of my_flask.py from flask import Flask app = Flask(__name__) @app.rou..
 about.md
about.md
10+년차[1] 개발자로 국내 주요 뱅킹, 농협, 행안부 등에 납품되는 방화벽 장비의 커널 로그를 처리하는 업무를 시작으로 숙박 플랫폼의 푸시, 알림톡 등을 개발했으며 오디오 플랫폼의 대용량 채팅 서버와 머신러닝 모델을 개발했습니다. 그리고 현재는 광고 데이터를 수집/가공/적재하는 Data Platform 셀과 DevOps 셀의 Tech Lead로 일을 하고 있습니다. 컨테이너와 마이크로 서비스, 서버리스에 관심이 많습니다. 한편, 커뮤니티에 기여하고자 Google 기술 전문가인 Google Developer Expert(GDE)와 HashiCorp Ambassador로 활동하고 있습니다.저와 연결 되길 원하시면 링크드인에서 뵙겠습니다! :-) ---[1] : 뒤에 숫자를 다 말하면 나이가 많아보여서 ..
예전에 리눅스 계통의 OS를 사용할 때 보면 이것저것 설치하면서 점점 덕지덕지해지는 느낌을 많이 받았었다. 나중에는 내가 뭘 설치했는지도 가물가물하고. 예를들어 개인용 워크스테이션으로 리눅스를 사용하면서 nginx 는 그다지 많이 활용 할일이 없는데 아주 가끔 브라우저를 통해 동료들과 무언가를 공유해야 하는 일이 있을 수 있다. 이때 로컬에 nginx를 설치해버리면 그야말고 일년에 한두번 사용하는 모듈을 관리까지 해줘야 하는 판국이 되버린다. 살아있는지, 죽어있는지, 포트 점유는 안하고 있는지 등등 깜빡했다가는 나중에 충돌날수도 있고. 아무튼 이런 고민을 현대에 와서는 docker가 모두 해결해준다. 이미 잘 구성되어 있는 컨테이너를 내려 받아서 사용하면 로컬 OS는 깔끔한 상태가 계속 유지된다. ngi..
스케일링 후 지혈이 안됐던 상황에 대한 기록. 생애 첫 스케일링은 화끈한 주말을 선물해줬다. 동네 병원에서 못뺀디는 사랑니 발치 때문에 대학병원에 갔고 겸사겸사 스케일링 받으시라고 해서 흔쾌히 수락. 사실 한번도 받아본적이 없어서 내심 걱정은 됐다. 치과를 20년 넘게 온적이 없으니까. 다행히 간호사의 현란함로 30-45분간 스케일링이 끝날 수 있었고 상쾌한(?) 기분을 느끼며 집으로 운전까지 하며 돌아왔다. 틈틈이 룸미러로 이를 확인하며 신기해하기도. 스케일링 후 약 1시간후에 아침식사를 했고 3시간 정도 후에는 노곤함에 낮잠을 잤다. 문제는 약 2시간 자고 일어나서 터졌다. 잠에서 깼는데 입안에 뭔가 가득 차있는 느낌. 흡사 선지국에 선지같은 느낌이랄까. 놀라서 화장실에 달려가 거울을 보니 입안은 온..
 오픈소스 오디오 편집툴 : Audacity
오픈소스 오디오 편집툴 : Audacity
대량의 오디오를 편집해야 하는 일이 있어서 막막했는데 Audacity를 만나고 걱정이 해소되었습니다. 여기서 제가 이야기하는 편집이라고 하면 긴 오디오 파일을 여러개로 나눈다던지, 아니면 소리가 없는 구간을 잘라내는 등의 행동을 이야기 합니다. 일단 Audacity는 윈도우와 Mac, 리눅스까지 모든 OS를 지원하는 오픈소스 프로젝트 입니다. 아래 경로에서 다운로드 받으실 수 있습니다. https://www.audacityteam.org/download/ 제 경우에는 ubuntu를 사용하기 때문에 아래와 같이 설치를 진행했습니다. sudo apt-get install audacity 설치가 완료되고 실행하면 아래와 같은 화면을 볼 수 있습니다. 이제 편집하려는 오디오 파일을 끌어다가 중앙에 회색 부분에 ..
python에 librosa를 통해 오디오 파일을 numpy로 읽어오는 코드가 아래와 같이 작성되어 있습니다. import librosa wave_path = '/home/caley/test.wav' sr = 44100 try: wav_np = librosa.core.load(wave_path, sr=sr)[0] except FileNotFoundError as e: print(e) wave_path에 test.wav는 실제로 존재하는 파일이지만 웬일인지 librosa는 에러를 발생시킵니다. FileNotFoundError: [Errno 2] No such file or directory: 'avconv': 'avconv' 이유는 librosa가 내부적으로 사용..
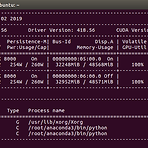 DataLoader num_workers에 대한 고찰
DataLoader num_workers에 대한 고찰
Pytorch에서 학습 데이터를 읽어오는 용도로 사용되는 DataLoader는 torch 라이브러리를 import만 하면 쉽게 사용할 수 있어서 흔히 공식처럼 잘 쓰고 있습니다. 다음과 같이 같이 사용할 수 있겠네요. from torch.utils.data import DataLoader 상세한 설명이 기술되어 있는 공식 문서는 아래 링크에서 살펴볼 수 있습니다. https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader 인자로 여러가지 파라미터를 넘길수 있는데 여기서 이야기하고자 하는 부분은 num_workers인데 공식문서의 설명은 다음과 같이 되어 있습니다. num_workers (int, optional) – how many sub..
- Total
- Today
- Yesterday