
 [번역] TensorFlow @ Google I/O ’19 Recap
[번역] TensorFlow @ Google I/O ’19 Recap
Google I/O에서 소개된 TensorFlow의 새로운 내용이 잘 정리된 글을 발견하고 번역해봤습니다. 아래 글의 원본은 TensorFlow @ Google I/O'19 Recap 에서 확인 하실 수 있습니다. 혹시 번역에 문제가 있거나 기타 문의가 있다면 말씀해주세요. :-) Google I/O'19가 끝났습니다! 5월 7-9일에 I/O에서 AI와 머신러닝 세션이 13개 다뤄졌는데요, TensorFlow는 2.0, AI for Mobile과 IoT 디바이스, TensorFlow용 Swift, TensorFlow Extended(TFX), TensorFlow.js, TensorFlow Graphics 등의 세션에서 만나 보실 수 있습니다. 이번 글에는 모든 세션 리스트와 링크가 담겨있습니다. 녹화된 ..
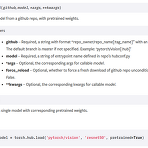 PyTorch Hub 톺아보기
PyTorch Hub 톺아보기
앞선 글에서 PyTorch Hub를 맛보고자 Load tacotron2+waveglow from PyTorch Hub 를 진행해봤습니다. 이번 글에서는 PyTorch Hub가 어떤 원리로 어떻게 사용되는 것인지 살펴보려고 합니다. 모든 내용을 살펴본 이후에는 우리의 커스텀 모델을 등록하는 것으로 글을 마무리 합니다. torch.hub.load() 자, 이전에 작성했던 코드에서부터 출발 해볼까요? # contents of waveglow.py import torch waveglow = torch.hub.load('nvidia/DeepLearningExamples', 'nvidia_waveglow') torch를 import하고 torch.hub.load() 함수를 통해 미리 학습된 모델을 불러왔습니다. 이..
 Load tacotron2+waveglow from PyTorch Hub
Load tacotron2+waveglow from PyTorch Hub
PyTorch Hub의 기세가 무섭습니다. 코드 구현체를 찾으려면 GitHub을 기웃거리면 되고 컨테이너를 찾으려면 Docker Hub로 가면 되듯이 얼마후면 딥러닝 모델 구현체를 찾기 위해서는 PyTorch Hub를 찾는 날이 올지도 모르겠습니다. 유명한 딥러닝 모델의 구현체들이 아래처럼 속속 등록되고 있는데요, 그중에 유독 눈에 띈 것은 Filter를 audio로 지정했을 때 나오는 Nvidia에서 구현한 Tacotron2, WaveGlow였습니다. 요즘 관심있게 보고 있던 모델이었기 때문에 PyTorch Hub와 함께 묶어서 살펴보기 좋겠다는 생각이 들어서 아래 링크를 참고해서 테스트를 진행해봤습니다. https://pytorch.org/hub/nvidia_deeplearningexamples_wa..
 DataLoader num_workers에 대한 고찰
DataLoader num_workers에 대한 고찰
Pytorch에서 학습 데이터를 읽어오는 용도로 사용되는 DataLoader는 torch 라이브러리를 import만 하면 쉽게 사용할 수 있어서 흔히 공식처럼 잘 쓰고 있습니다. 다음과 같이 같이 사용할 수 있겠네요. from torch.utils.data import DataLoader 상세한 설명이 기술되어 있는 공식 문서는 아래 링크에서 살펴볼 수 있습니다. https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader 인자로 여러가지 파라미터를 넘길수 있는데 여기서 이야기하고자 하는 부분은 num_workers인데 공식문서의 설명은 다음과 같이 되어 있습니다. num_workers (int, optional) – how many sub..
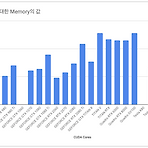 compare-GPUs for machine learning
compare-GPUs for machine learning
쏟아지는 GPU 속에서 무엇을 선택해야 하는지 고민한 경험은 누구나 있을 듯 합니다. 가격도 만만치 않을 뿐더러 구입했을 때 원하는 목적대로 사용하지 못하면 낭패니까요. 저도 이런 경험이 있습니다. 이런 고민 해소를 위해 벤치마킹 자료까지는 아니더라도 그래픽 카드를 나열해두고 비교할 수 있는 자료가 있었으면 좋겠다고 생각한 적이 있습니다. 그래서 틈틈이 준비해봤죠. 우선 그래픽카드를 선택하는데 가장 큰 부분을 차지하는 CUDA 코어를 비교해봤습니다. (CUDA 코어로 명시한건 현재 NVIDIA 제품만 대상으로 했기 때문입니다) 그래픽카드가 쌍으로(per GPU) 탑재되거나, 세부 모델이 나뉘는 경우는 그래프에는 표기하지 않았습니다. 또한 현재는 NVIDIA제품만 비교했지만 시간 될 때 지속적으로 추가시킬..
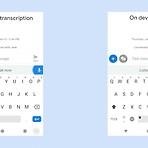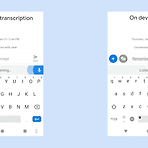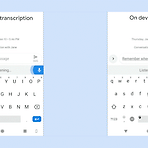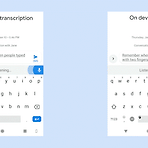 Towards end-to-end speech recognition
Towards end-to-end speech recognition
본 게시물에서 사용된 대부분의 이미지는 아래 링크로부터 첨부되었으며 해당 자료를 통해 많은 영감을 얻었습니다. http://iscslp2018.org/images/T4_Towards%20end-to-end%20speech%20recognition.pdf 하루가 멀다하고 기계가 인간을 뛰어넘는 분야가 늘어나고 있습니다. 구글 딥마인드를 필두로 여러 분야가 정복되고 있는데 2017년 알파고는 절대 정복 할 수 없다고 평가되던 바둑 분야에서 이세돌 9단을 상대로 승리를 거뒀으며 알파스타의 등장으로까지 이어졌습니다. 알파스타는 세계 1위에 프로게이머를 상대로 거둔 승리는 아니었지만 게임 분야에서 충분한 가능성을 보여줬습니다. 아무튼, 여러분야에서 두각을 나타내고 있는 기계학습은 이미지 인식의 경우에는 2015년..
>>> import tensorflow as tf ModuleNotFoundError: No module named 'numpy.core._multiarray_umath' ImportError: numpy.core.multiarray failed to import The above exception was the direct cause of the following exception: Traceback (most recent call last): File "", line 968, in _find_and_load SystemError: returned a result with an error set ImportError: numpy.core._multiarray_umath failed to import I..
 Usage TPU in Google Colaboratory
Usage TPU in Google Colaboratory
Colab의 사용권한을 신청하고 accept 되어야만 사용할 수 있었던 시절이 있었는데 이제는 너무나 보편화 되었고 K80 GPU는 물론 TPU까지 마음껏 굴려볼 수 있는 상태가 되었습니다. 참고글: Google Colaboratory를 아시나요? 하지만 막상 찾아보면 TPU 사용예제가 많이 안보이는데 TensorFlow 공식 예제가 너무 잘되어 있기 때문일까요? 아무튼 한글 자료는 턱없이 부족한데 도움이 될 누군가를 위해 메모로 남겨두도록 합니다. 이 글은 tf 1.13 버전을 기반으로 하고 있기 때문에 keras가 공식적으로 tensorflow 안에 모듈로 자리 잡고 있는 상태입니다. 다음은 TensorFlow 공식 홈페이지에 있는 MNIST 예제코드입니다. import tensorflow as tf..
 Use multiple versions of CUDA
Use multiple versions of CUDA
우리가 작업하는 다양한 소스코드는 때로는 서로 다른 버전의 cuda 를 사용하기도 합니다. 그리고 물리적으로 한 대의 머신을 공유해서 사용한다고 했을 때 여러 버전의 cuda 를 이용하는 것은 매우 당연한 일이겠습니다. 이번 글에서는 어떻게 그것이 가능한지에 대한 이야기를 짧게 공유합니다. 1. cuda 설치 ( https://developer.nvidia.com/cuda-downloads )링크에 접속해서 cuda 를 다운로드 받습니다. OS 부터 하나씩 선택해나가면 최종적으로 아래와 같은 화면을 볼 수 있습ㄴ다. 이 글이 작성된 시점 기준으로는 cuda 10.1 이 최신버전이라 위에 링크에 접속하면 다음 버전으로 가이드가 됩니다.다운로드 받은 cuda 는 위에 설명에 있는 것처럼 터미널에서 실행해주면..
 ImportError: libcudnn.so.7: cannot open shared object file: No such file or directory
ImportError: libcudnn.so.7: cannot open shared object file: No such file or directory
아래와 같이 tensorflow-gpu 를 설치하였고, pip install tensorflow-gpu==1.9코드상에서 import 를 하려고하니 에러가 발생했습니다. (tensorflow_p36) $ python Python 3.6.5 |Anaconda, Inc.| (default, Apr 29 2018, 16:14:56) [GCC 7.2.0] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import tensorflow as tf Traceback (most recent call last): File "/home/caley/anaconda3/envs/tensorflow_p36/lib/python3..
 [Kaldi] voxforge online demo
[Kaldi] voxforge online demo
http://kaldi-asr.org/ 이 글을 읽고 있다는 것은 sample 스크립트 학습을 끝냈다는 이야기인데 일단 축하드립니다. 이번 글에서는 학습시킨 데이터를 기반(은 이미 공개되어 있는 모델셋)으로 demo 를 해볼텐데 kaldi 에 있는 voxforge 에서는 두 가지 방식으로 데모를 지원합니다. 여기에는 1) microphone 의 입력에 따라 실시간으로 음성을 text 로 변환하는 live 모드와 2) 음성파일을 text로 변환하는 simulated 모드가 있습니다.일단 egs/voxforge 로 이동해서 보면 다음과 같이 세 개의 디렉터리가 존재합니다. $ tree -L 1 . ├── gst_demo ├── online_demo └── s5 3 directories, 0 files s5 ..
 [Kaldi] Run sample script on Mac
[Kaldi] Run sample script on Mac
http://kaldi-asr.org/ 이번 글에는 Kaldi 에서 제공하는 샘플 스크립트를 통해 기본적인 테스트를 진행하는 과정을 살펴봅니다. 테스트를 진행하기 전에 잠깐 Kaldi 의 디렉터리 구조를 살펴볼 필요가 있는데요, 소스코드를 내려받고 살펴보면 아래와 같은 구조를 확인할 수 있습니다. $ tree -L 1 . ├── COPYING ├── INSTALL ├── README.md ├── egs/ ├── misc/ ├── scripts/ ├── src/ ├── tools/ └── windows/ 6 directories, 3 files 6개의 디렉터리와 3개의 파일로 구성되어 있군요. 파일은 설치 과정이 메모되어 있는 INSTALL 과 프로젝트 소개가 있는 README.md, 그리고 카피라이트인 ..
 [Kaldi] install ( feat. on Mac )
[Kaldi] install ( feat. on Mac )
http://kaldi-asr.org/Kaldi Speech Recognition Toolkit 의 동작에 대한 기본 테스트를 MacOS 에서 진행한 경험을 기록 합니다. 보통의 오픈소스를 살펴보면 READMD.md 와 같은 파일을 두고 그 안에서 설치 가이드를 제공하고 있는데 Kaldi 는 README 에서 그런 언급을 하지 않고 대신 INSTALL ( plain-text ) 파일을 제공합니다. 그럼 이제 INSTALL 파일을 확인하고 설치를 진행해보도록 합니다.우선 GitHub 을 통해 공개되어 있는 Kaldi 소스코드를 내려 받습니다. git clone https://github.com/kaldi-asr/kaldi.git 소스 디렉터리 홈에 있는 INSTALL 파일을 열어보면 다음과 같은 내용이 쓰..
- Total
- Today
- Yesterday