
 [책] 자연어 처리 딥러닝 캠프
[책] 자연어 처리 딥러닝 캠프
딥러닝 기반의 자연어 처리를 기초부터 심화까지 두루 다루는 책이 한빛미디어에서 출간되었습니다. 바로 자연어 처리 딥러닝 캠프인데요, 이 책의 모든 예제는 PyTorch 1.0을 기반으로 다루고 있으며 딥러닝의 기초 서적이 아니기 때문에 목적/손실 함수, 선형/로지스틱 회귀, 그래디언트 디센트 정도는 이미 숙지하고 있다는 가정하에 내용을 진행합니다. 책의 표지에서부터 PyTorch의 기운이 느껴집니다. 책의 모든 페이지가 컬러로 되어 있어서 꽤 세련된 느낌을 주고 패스트캠퍼스에서 진행한 강의가 바탕이 되어서인지 내용 구성이 좋아서 훌훌 잘 읽힙니다. 매 단원이 끝날때마다 딥러닝의 대가들(제프리 힌튼, 클로드 셰넌, 얀 르쿤 등)이 스케치 이미지로 등장하는데 누가 등장할지 궁금해서 더 빨리 읽게 되는것 같기..
 PyTorch Hub 톺아보기
PyTorch Hub 톺아보기
앞선 글에서 PyTorch Hub를 맛보고자 Load tacotron2+waveglow from PyTorch Hub 를 진행해봤습니다. 이번 글에서는 PyTorch Hub가 어떤 원리로 어떻게 사용되는 것인지 살펴보려고 합니다. 모든 내용을 살펴본 이후에는 우리의 커스텀 모델을 등록하는 것으로 글을 마무리 합니다. torch.hub.load() 자, 이전에 작성했던 코드에서부터 출발 해볼까요? # contents of waveglow.py import torch waveglow = torch.hub.load('nvidia/DeepLearningExamples', 'nvidia_waveglow') torch를 import하고 torch.hub.load() 함수를 통해 미리 학습된 모델을 불러왔습니다. 이..
 Load tacotron2+waveglow from PyTorch Hub
Load tacotron2+waveglow from PyTorch Hub
PyTorch Hub의 기세가 무섭습니다. 코드 구현체를 찾으려면 GitHub을 기웃거리면 되고 컨테이너를 찾으려면 Docker Hub로 가면 되듯이 얼마후면 딥러닝 모델 구현체를 찾기 위해서는 PyTorch Hub를 찾는 날이 올지도 모르겠습니다. 유명한 딥러닝 모델의 구현체들이 아래처럼 속속 등록되고 있는데요, 그중에 유독 눈에 띈 것은 Filter를 audio로 지정했을 때 나오는 Nvidia에서 구현한 Tacotron2, WaveGlow였습니다. 요즘 관심있게 보고 있던 모델이었기 때문에 PyTorch Hub와 함께 묶어서 살펴보기 좋겠다는 생각이 들어서 아래 링크를 참고해서 테스트를 진행해봤습니다. https://pytorch.org/hub/nvidia_deeplearningexamples_wa..
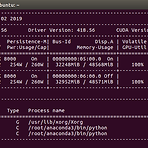 DataLoader num_workers에 대한 고찰
DataLoader num_workers에 대한 고찰
Pytorch에서 학습 데이터를 읽어오는 용도로 사용되는 DataLoader는 torch 라이브러리를 import만 하면 쉽게 사용할 수 있어서 흔히 공식처럼 잘 쓰고 있습니다. 다음과 같이 같이 사용할 수 있겠네요. from torch.utils.data import DataLoader 상세한 설명이 기술되어 있는 공식 문서는 아래 링크에서 살펴볼 수 있습니다. https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader 인자로 여러가지 파라미터를 넘길수 있는데 여기서 이야기하고자 하는 부분은 num_workers인데 공식문서의 설명은 다음과 같이 되어 있습니다. num_workers (int, optional) – how many sub..
- Total
- Today
- Yesterday