
 웹크롤러 scrapy를 소개합니다
웹크롤러 scrapy를 소개합니다
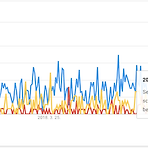
scrapy는 웹사이트에서 필요한 데이터를 추출하는 오픈소스 프레임워크입니다. 네, 많고 많은 crawler 중에 하나입니다. 혹시 듣보잡 아니냐고요? 네, 뭐 구글 트렌드로 다른 크롤러와 비교해보면 크게 뒤떨어지는 건 사실입니다. (지난 5년간 대한민국 기준 트렌드 자료입니다. 파란색이 selenium, 노란색이 beautifulsoup, 빨간색이 scrapy) GitHub에 Star를 인기의 척도라고 본다면 scrapy는 상당히 인기 있는 프레임워크로 볼 수 있습니다. 이 말인즉, 개발자에게는 꽤나 인기 있는 크롤러라는 겁니다. 아래를 보세요. 스타 수가 무려 41.1k 개고 아직도 활발히 개발되고 있습니다. scrapy는 가볍고, 빠르고, 확장성이 좋습니다. 개발자는 파이썬 기반으로 spider라고..
 GCE 위에서 Google 계정 복구
GCE 위에서 Google 계정 복구
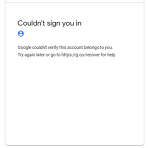
개인적인 업무 자동화를 위해 GCE 위에 python crawler 를 하나 개발하고 있는데 이게 영 잘 안되는거다. 처음에는 selenium 을 잘못 사용했나 싶기도하고 HTML 을 잘못 파싱했나 싶은 의심도 들었지만 해당 코드가 Local PC 에서는 정상적으로 동작 하는 것이 확인되었다. 무엇이 문제였을까? 문제를 확인하기 위해 에러 포인트 위치에서 아래와 같이 selenium 의 스냅샷 함수를 이용해서 페이지의 실제 화면을 확인해보았다.browser.get_screenshot_as_file('error.png') 확인결과 놀랍게도 아래와 같은 내용이 확인되었다. 왜 계정이 이렇게 되었는지는 알 수 없다. 아니면 Gmail 자체적으로 클라우드에서의 접근을 막고 있는지도 모른다. 일단 로컬에서 htt..
- Total
- Today
- Yesterday