
티스토리 뷰
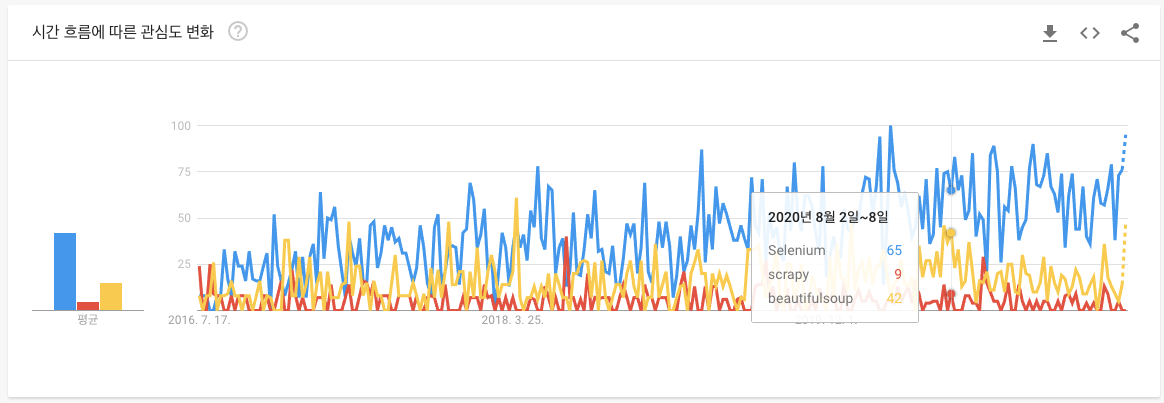
scrapy는 웹사이트에서 필요한 데이터를 추출하는 오픈소스 프레임워크입니다. 네, 많고 많은 crawler 중에 하나입니다. 혹시 듣보잡 아니냐고요? 네, 뭐 구글 트렌드로 다른 크롤러와 비교해보면 크게 뒤떨어지는 건 사실입니다. (지난 5년간 대한민국 기준 트렌드 자료입니다. 파란색이 selenium, 노란색이 beautifulsoup, 빨간색이 scrapy)
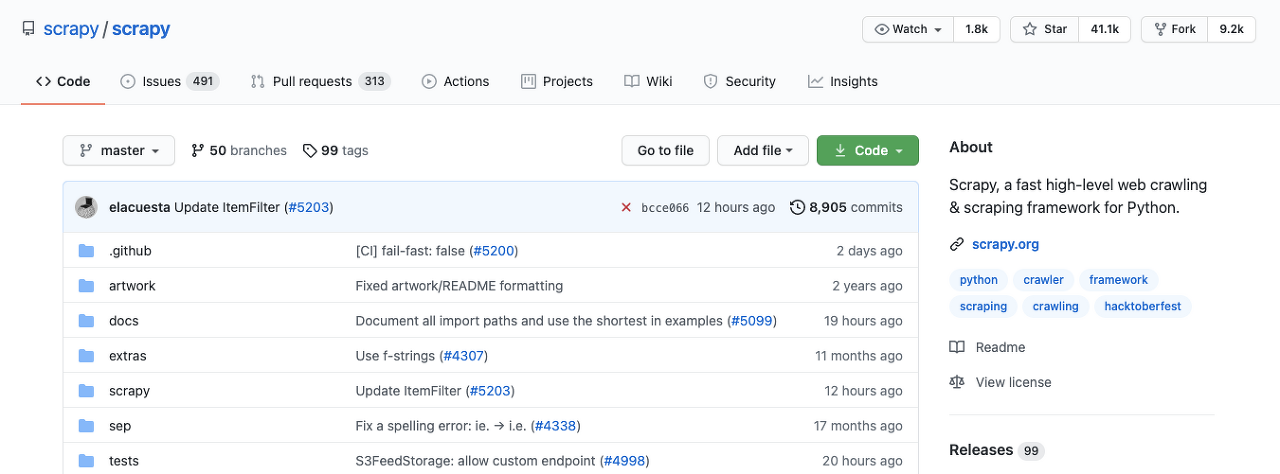
GitHub에 Star를 인기의 척도라고 본다면 scrapy는 상당히 인기 있는 프레임워크로 볼 수 있습니다. 이 말인즉, 개발자에게는 꽤나 인기 있는 크롤러라는 겁니다. 아래를 보세요. 스타 수가 무려 41.1k 개고 아직도 활발히 개발되고 있습니다.
scrapy는 가볍고, 빠르고, 확장성이 좋습니다. 개발자는 파이썬 기반으로 spider라고 하는 코드를 작성하면 되거든요.

# 주요 특징
scrapy의 특징은 아래와 같이 정리됩니다.
- 비동기 네트워킹 라이브러리(asynchronous networking library)인 Twisted를 기반으로 하기 때문에 매우 우수한 성능을 발휘합니다. 또한 셀레니움과 마찬가지로 XPath, CSS 표현식으로 HTML 소스에서 데이터 추출이 가능합니다. 한편, 셀레니움과 다르게 webdriver를 사용하지 않습니다.
- 셀레니움은 페이지를 렌더링 하기 위해 필요한 js, css 그리고 image 파일까지 불러오며 난리가 나죠. 하지만 scrapy는 지정된 url만 조회합니다. 그렇기 때문에 scrapy가 셀레니움보다 가볍고 빠른 퍼포먼스를 낼 수 있는 겁니다. curl 커맨드, 혹은 python에서 requests 라이브러리를 사용해서 URL에 get 메소드를 날리는 걸 상상해보세요. 간결한 구성으로 빠르게 응답받을 수 있겠죠!
# 예제 코드
다음으로 예제 코드를 살펴보겠습니다. ( 공식 코드에 main만 추가한 코드입니다 )
# quotes_spider.py
import scrapy
from scrapy.crawler import CrawlerProcess
class QuotesSpider(scrapy.Spider):
name = "quotes"
def start_requests(self):
urls = [
'http://quotes.toscrape.com/page/1/',
'http://quotes.toscrape.com/page/2/',
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
page = response.url.split("/")[-2]
filename = f'quotes-{page}.html'
with open(filename, 'wb') as f:
f.write(response.body)
self.log(f'Saved file {filename}')
if __name__ == '__main__':
process = CrawlerProcess(setting)
crawler = process.create_crawler(QuotesSpider)
process.crawl(crawler)
process.start()코드를 보면 대충 감이 오시나요? main 부분은 신경 쓰지 않으셔도 됩니다. 크롤러를 초기화하는 과정으로 사실 이 부분 없이도 터미널에서 아래처럼 QuotesSpider를 직접 실행시키는 것도 가능하니까요.
$ scrapy crawl quotes코드를 잠시 살펴보면, 주어진 URL 두 개에 대해서 request(get)를 보내고 그 결과를 callback으로 처리하는 로직입니다. parse 이외에도 콜백은 계속 연결할 수 있습니다. 예를 들어 "로그인 → 페이지 이동 → 데이터 조회 → 데이터 다운로드" 이런 파이프라인을 생각해 볼 수 있겠네요. 위 예제는 quotes.toscrape.com에서 1, 2 페이지를 방문하고 있는데 이처럼 여러 가지 액션이 동시에 이루어져야 하는 경우 막강하게 활용할 수 있겠습니다. 한편, callback처럼 에러 핸들링을 위한 errback 도 지원합니다. callback처럼 errback도 붙여서 사용하시면 됩니다. 아래는 공식 예제의 일부입니다.
import scrapy
from scrapy.spidermiddlewares.httperror import HttpError
from twisted.internet.error import DNSLookupError
from twisted.internet.error import TimeoutError, TCPTimedOutError
class ErrbackSpider(scrapy.Spider):
name = "errback_example"
start_urls = [
"http://www.httpbin.org/", # HTTP 200 expected
"http://www.httpbin.org/status/404", # Not found error
"http://www.httpbin.org/status/500", # server issue
"http://www.httpbin.org:12345/", # non-responding host, timeout expected
"http://www.httphttpbinbin.org/", # DNS error expected
]
def start_requests(self):
for u in self.start_urls:
yield scrapy.Request(u, callback=self.parse_httpbin,
errback=self.errback_httpbin,
dont_filter=True)
def parse_httpbin(self, response):
self.logger.info('Got successful response from {}'.format(response.url))
# do something useful here...
def errback_httpbin(self, failure):
# log all failures
self.logger.error(repr(failure))
# in case you want to do something special for some errors,
# you may need the failure's type:
if failure.check(HttpError):
# these exceptions come from HttpError spider middleware
# you can get the non-200 response
response = failure.value.response
self.logger.error('HttpError on %s', response.url)
elif failure.check(DNSLookupError):
# this is the original request
request = failure.request
self.logger.error('DNSLookupError on %s', request.url)
elif failure.check(TimeoutError, TCPTimedOutError):
request = failure.request
self.logger.error('TimeoutError on %s', request.url)호출에 성공하면 callback으로 붙어있는 parse_httpbin이 실행되고, 어떤 이유로든 실패하게 되면 errback으로 선언되어 있는 errback_httpbin이 호출되는 구조입니다.
예제 코드까지 살펴봤는데 사실 여기까지만 보면 curl이나 python의 requests 등의 라이브러리를 사용하는 것과 차이를 느끼지 못할 수도 있습니다. 하지만 조금 더 심화로 들어가게 되면 scrapy에서 다양한 configuration이 있습니다. 다른 라이브러리로 개발한다면 밑바닥부터 신경 써야 하는 모든 것을 하나의 프레임워크로 제공받게 된다는 걸 알게 됩니다. 이를테면 데이터 다운로드 타임아웃을 설정한다던가, 각 request 간에 random 한 텀(사람의 실제 액션처럼 보이기 위한)을 둔다던지 말이죠. 상세한 설정은 아래 링크에서 확인 가능합니다.
https://docs.scrapy.org/en/latest/topics/settings.html
# 결론
위에서 확장성이 좋다는 이야기도 했는데 맞습니다. 미들웨어를 새로 개발한다거나 파이프라인을 연결하는 게 아주 쉽기 때문이에요. 예를 들면 proxy 처리를 위한 미들웨어, 데이터 파이프라인처럼요. 하지만 scrapy에는 큰 단점이 있습니다. javascript 지원이 힘들다는 건데요, ajax/pjax로 데이터가 갱신되는 웹페이지라면 원하는 데이터를 추출하는 게 쉽지 않습니다. scrapy+selenium으로 극복도 가능하지만 그럴 거면 그냥 셀레니움 쓰는 게 낫지 않냐며... 아무튼, 한 개 사이트 안에서 여러 페이지를 돌아다니며 핸들링해야 하는 데이터가 많을 때. 그리고 그 페이지가 javascript의 영향이 적을 때 scrapy는 selenium보다 훨씬 더 좋은 선택지가 될 수 있겠습니다. 데이터 수집의 여정에 scrapy가 도움이 될 수 있기를 바랍니다!
'개발 > python' 카테고리의 다른 글
| SQLAlchemy add, flush, commit (1) | 2021.04.27 |
|---|---|
| python 프로그램 메모리 사용량 확인 (14) | 2021.02.20 |
| Hello Poetry (Dependency Management for Python) (0) | 2021.02.06 |
| FastAPI 톺아보기 - 부제: python 백엔드 봄은 온다 (12) | 2021.01.30 |
| librosa.util.exceptions.ParameterError: data must be floating-point (0) | 2019.06.13 |
- Total
- Today
- Yesterday