

 웹크롤러 scrapy를 소개합니다
웹크롤러 scrapy를 소개합니다
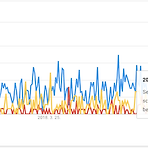
scrapy는 웹사이트에서 필요한 데이터를 추출하는 오픈소스 프레임워크입니다. 네, 많고 많은 crawler 중에 하나입니다. 혹시 듣보잡 아니냐고요? 네, 뭐 구글 트렌드로 다른 크롤러와 비교해보면 크게 뒤떨어지는 건 사실입니다. (지난 5년간 대한민국 기준 트렌드 자료입니다. 파란색이 selenium, 노란색이 beautifulsoup, 빨간색이 scrapy) GitHub에 Star를 인기의 척도라고 본다면 scrapy는 상당히 인기 있는 프레임워크로 볼 수 있습니다. 이 말인즉, 개발자에게는 꽤나 인기 있는 크롤러라는 겁니다. 아래를 보세요. 스타 수가 무려 41.1k 개고 아직도 활발히 개발되고 있습니다. scrapy는 가볍고, 빠르고, 확장성이 좋습니다. 개발자는 파이썬 기반으로 spider라고..
개발/python
2021. 7. 15. 16:43
최근에 올라온 글
최근에 달린 댓글
글 보관함
- Total
- Today
- Yesterday