
 질의응답 QnA 웹 서비스 제작기
질의응답 QnA 웹 서비스 제작기
Vue.js 로 웹 개발을 시작한지 한달 남짓. 뷰스러운 것 보다는 오히려 html, css, javascript 가 발목을 잡는다. 이래서 어느 분야던지 기초가 중요하다고 하는거다. 애초에 웹 개발쪽은 쳐다본 적도 없으니 그럴 수 밖에 없지. 아무튼 고작 한달 했다고 쓸데없이 자신감만 생겨서는 우연히 알게된 좋은 플랫폼을 개인 프로젝트로 흉내내고 싶은 욕심이 생겼다. (사내 세미나를 통해 알게 됨)플랫폼은 비교적 간단하다. 용도는 콘퍼런스장에서 Q&A 시간에 질문을 받고 Timeline 을 보여준다. 좋은 질문이라고 생각되면 누구나 해당 질문에 upvote 를 할 수 있다. 익명으로 질문을 포스팅 하거나 닉네임을 적을 수도 있다. 그리고 타임라인을 여러가지 방식으로 정렬할 수 있다. 예를들면 시간, u..
화면에서 select box 가 선택될 때 클릭 이벤트를 받고 이때 v-model 값을 통해 무언가를 해야하는 경우가 생겼다. 심플하게는 아래와 같은 코드 모양새가 되겠다. {{ type }} Changed 함수를 살펴보면 다음과 같다. Changed() { if ( this.selected == "pig" ) this.type = "animal"; if ( this.selectd == "apple" ) this.type = "fruit"; }코드상으로 의도는 select box 에서 pig 를 선택하는 경우 화면에 pig 는 animal 이라고 표현하려고 한다. 혹은 apple 를 선택하면 fruit 로 표기한다. 하지만 놀랍게도(!) 코드는 의도와 반대로 동작한다. 왜냐하면 click 이벤트는 v-m..
Node.js 를 시작하면서 제일 먼저, 혹은 많이 듣게 되는 이야기가 콜백지옥이다. 그런 상태로 노드를 접하고 사용하기 시작하니 혼란을 부르는 부분이 있는데 이번에 콜백(callback)을 대해 정리를 하는 시간을 갖도록 해본다. 언어든 기술이든 기초가 중요하고 기초를 탄탄히 하면 콜백지옥에서 어느순간 자연스럽게 벗어날 수 있지 않을까? 노드(정확히는 자바스크립트)에서 함수는 일급 객체로 취급된다. 위키백과를 참고하면 일급 객체가 되기 위해서는 아래 조건이 충족되어야 한다.변수나 데이터 구조안에 담을 수 있다.파라미터로 전달 할 수 있다.반환값(return value)으로 사용할 수 있다.할당에 사용된 이름과 관계없이 고유한 구별이 가능하다.동적으로 프로퍼티 할당이 가능하다.이 말을 이해하기 위해서 아..
 pm2 모듈을 부트 스크립트로 등록하기
pm2 모듈을 부트 스크립트로 등록하기
pm2 에서 관리되는 모듈은 대부분이 데몬 형태이고 각각은 메모리에 항상 상주해야 하는 서비스일 것이다. 운영중에 죽는 모듈은 pm2 에 의해서 자동으로 재시작되겠지만 시스템이 재부팅된다면 어떨까? 당연히 답은 No 다. 아직 우리는 pm2 에게 그런 일을 시키지 않았으니까.리눅스의 부팅 시스템 init.d 같은 곳에 스크립트를 만들어 넣는 등의 방법으로 부팅시에 우리 모듈을 시작시킬 수 있다. 하지만 이런 귀찮은 절차를 이미 pm2 에서는 자동으로 제공해주고 있다. 옵션 하나만 입력하면 된다. 바로 아래서 살펴보도록 하자. 시스템에는 우리의 모듈 server 가 돌고 있는 상황이다.현재 돌고 있는 서비스에 대해서 부팅 시스템에 등록하는 방법은 매우 간단하다. pm2 에 startup 옵션을 넘겨주면 된..
 프로젝트 종료하기
프로젝트 종료하기
Google Cloud Platform (GCP) 를 현업에서 이용하는 케이스가 아니면 대부분 퍼블릭 클라우드를 공부하는 목적으로 이용하는 경우가 많을 것이다. 이 경우에는 1년동안 사용할 수 있는 $300 크레딧으로 클라우드를 충분히 즐길 수 있다. 1년이 지난다고 계정이 (유료로) 자동 전환되지 않기 때문에 필요 시에 유료 계정으로 전환해줘야 한다. 그대로 방치하는 경우에는 사용하던 모든 기능이 잠기기 때문에 아차하는 순간 소중한 데이터를 놓칠 수 있게 된다. 또한 1년이 지날 때 공식적으로는 유로로 자동 전환이 되지 않는다고 되어 있지만 아주 간혹 청구되는 경우가 있을 수 있다고 한다. - 고객센터에 연결해서 이런저런 과정을 거치면 환급받을 수 있겠지만 여간 귀찮은 일이 아닐 수 없겠다.아무튼 이런..
노드를 더 우아하게 해주는 주변 프로그램인 npm 을 이해하도록 해보자. npm 은 Node.js Package Manager 로 단어 그대로 패키지 관리를 돕는다. 언뜻보면 python 의 pip 와 그 형상이 비슷해보이기도 한다. 하지만 npm 은 pip 처럼 패키지를 설치하는 기능을 포함하는 것으로 이해하는게 맞다. 이 장황한 이야기를 풀어내기 위해 API 서버를 노드 프로그램으로 만들어가며 이야기 하도록 하자. 우선 노드 프로젝트를 시작할 때 server.js 부터 만드는게 아니라 npm 을 이용해서 프로젝트를 생성한다. $ npm init 이렇게하면 몇가지 문답을 거친후 디렉터리에 package.json 파일이 생성된다. 대략 가볍게 훑어보고 적당한 값을 입력하자. 빈 값으로 엔터를 입력하게되면..
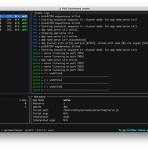 노드를 더 우아하게. pm2 이야기
노드를 더 우아하게. pm2 이야기
이번에는 노드를 더 우아하게 사용할 수 있도록 돕는 PM2 에 대해 이야기를 해본다. PM2 는 Process Manager 의 약자로 이미 단어에서 모든게 설명 되는데 노드 프로세스를 관리해주는 역할을 한다. 아래에서 간단한 노드 프로그램을 기반으로 PM2 를 차근차근 이해하도록 하자. 보통 서버에 데몬 형태의 application 을 개발하게 되면 여러가지 것들을 신경써야 했다. 이를테면 application 에서 남기는 로그에 대한 처리( filesystem 을 이용해서 남기는 방법, 날짜 포함, rotate, etc ), 프로세스가 죽었을 때에 대한 처리( restart ), 부팅시에 자동 실행 등 무수히 많은 것들이 있다. 이런 귀찮은 것들을 몽땅 관리해주는 프로세스가 있다면 얼마나 편할까? (..
crontab 은 어떤 주기적인 처리를 꽤 영리하게 도와주는 Linux 시스템에 없어서는 안될 스케줄러이다. 특정시간에 파일시스템을 정리한다던가 주기적으로 알람을 발송한다던가 또는 시스템 자원을 모니터링한다던가 등등 많은 활용분야가 있겠다.이렇게 편한 크론탭을 사용할 때 잊어서는 안되는 중요한 사실이 있다. 바로 스케줄러에 의해 실행되는 job 은 [cron] 권한으로 실행된다는 점인데 그렇기 때문에 우리는 아래 두가지 사항을 항상 체크해야 한다.스케줄링 하려는 명령어의 PATH (환경변수)가 cron 에게 있는지.스케줄링 하려는 명령어를 cron 이 실행시킬 수 있는지 ( = 권한이 있는지 )첫번째 내용의 경우에는 그냥 습관처럼 명령어의 절대경로를 써주면 해결된다. 극단적인 예를들어 리눅스의 date ..
 [Redis] 운영에 필요한 최소한의 지식
[Redis] 운영에 필요한 최소한의 지식
Redis 데이터 타입에 대한 글은 인터넷에 널리고 널렸다. 당장 그 이론을 한번 더 언급하는 것은 괜한 비용 낭비로 생각되니 실전 운영에 필요한 기초 예제 몇 가지를 공유해본다. 이번 글에서는 List 와 Hash 에 대해 집중적으로 다룬다.List리스트 형태로 데이터를 관리할 때 용이하게 사용되는 데이터 타입이다. 데이터는 LPUSH, RPUSH 로 적재하고 LPOP, RPOP 으로 꺼낼 수 있다. 한편 조회는 LRANGE, LLEN 을 사용한다. 아래에서 데이터를 확인하며 구체적으로 알아보자.이러한 리스트가 있을 때 LPUSH, LPOP 은 배열의 좌측에 있는 데이터를 제어할 수 있다. 즉, LPUSH 로 새로운 데이터 8을 넣게 되면 아래와 같이 데이터가 들어간다. 이때 LPOP 도 마찬가지로 좌..
 Cloud TPU 사용하기
Cloud TPU 사용하기
@아래 내용은 TPU quota 가 신청되어 있어야 사용 가능한 부분입니다. 참고 하시기 바랍니다.TPU 가 일반에 공개된 것과 비슷한 시기에 Google Compute Engine (GCE) 에도 TPU 메뉴가 생성되었다. 와우, 이제 우리의 인스턴스 내에서 TensorFlow 를 통해 기계학습을 진행할 때 TPU 를 지정해서 사용할 수 있게 된 것이다. 이 부분은 CloudML 과는 전혀 상관이 없으므로 오해하지 않도록 한다. Google Cloud Platform (GCP) 의 모든 기능이 그러하듯이 Cloud TPU 도 API 사용 설정을 통해 기능을 활성화시켜야 사용할 수 있다. 기능을 활성화하면 잠시 후 아래와 같은 메뉴를 볼 수 있다. 일단 TPU 노드를 생성해보자. (빠른 시작 사용을 통해..
 [소식] 드디어 TPU를 일반에 공개
[소식] 드디어 TPU를 일반에 공개
구글클라우드 안에서 우리는 CPU, GPU, TPU를 사용할 수 있다는 이야기를 항상 들어왔다. 이세돌 9단과 알파고의 경기때부터 TPU는 놀라운 성능을 보여줬지만 정작 일반에 공개되어 있지 않았기 때문에 기계학습을 다루는 분들께는 사실 그림의 떡이나 마찬가지였다.- 일부 기업은 별도의 신청 프로세스를 통해 이미 사용할 수 있었다. 아무튼, 그러던 TPU가 드디어 일반에 공개되었다. AutoML과 마찬가지로 다소 까다로울 수 있는 심사 과정이 있지만 사용해볼 수 있다는 사실에 많은 엔지니어가 벅차오를 것으로 기대된다. 자세한 설명은 아래 링크로 대체한다. https://cloud.google.com/tpu/ 제일 해보고 싶은 것이 TF 예제를 TPU로 돌렸을 때 K80, P100 대비 얼마나 차이나는지 ..
윈도우에 질려 리눅스로 넘어온 대부분의 사용자들이 가장 불편하게 느끼는 부분이 바로 터미널에 대한 높은 의존도일 것이다. 리눅스의 높은 진입장벽은 그렇게 만들어진다. 사실 요즘 세상이 좋아져서 리눅스도 윈도우 뺨치는 GUI 가 많이 등장했지만 우리가 리눅스를 사용하는 근본적인 이유는 시스템의 모든 것을 스마트하게 제어할 수 있는 터미널의 존재 때문이니 GUI 는 중요하지 않다. (윈도우에는 command 가 터미널의 역할을 수행한다고 할 수 있다.) 어느정도 터미널을 익숙하게 사용할 수 있게되면 그때부터는 그 매력에서 빠져나오지 못할 것이다. 터미널을 사용한다는 것은 다양한 shell 을 통해 시스템의 환경을 설정하고 조작하는 것을 의미하겠다. shell 은 시스템 제어와 모니터링을 위한 다양한 명령어를..
 CloudML - 분산학습 아키텍처
CloudML - 분산학습 아키텍처
이전 편까지 우리는 CloudML 이 무엇인지 살펴보고 모델을 클라우드에 던지고 결과를 받는 등 CloudML 전체 시나리오에 대한 이야기만 했다. 이번 글에서는 ML job 의 분산학습 아키텍처를 살펴보고 이해하도록 한다. 함께보면 좋은 글CloudML - 개념 CloudML - 기본 CloudML - 실전 심화Scale tierCloudML 은 training 을 돌릴 서버의 사양을 조정할 수 있는 Scale-tier 옵션을 제공하는데 그 안에는 BASIC, STANDARD_1, PREMIUM_1, BASIC_GPU 그리고 CUSTOM 까지 총 다섯가지 종류가 있다. CUSTOM 을 알아보기 전에 다른 네 가지 방식의 사양을 보자. Cloud ML Engine scale tier Compute Eng..
 CloudML vs GCE
CloudML vs GCE
앞에서 CloudML 에 대한 이야기를 많이 했는데 사실 일반 VM instance (Compute Engine) 로 머신러닝을 이용하는 것에 비해 무엇이 좋은지 자세히 다루지 않았다. 이번 글을 통해 몇 가지 장점을 살펴보도록 하자. 비용아마도 가장 큰 장점이 되겠다. 다른 작업은 몰라도 머신러닝/딥러닝은 고사양 시스템을 필요로 하며 프로젝트에 따라 훈련시간이 굉장히 오래걸리기도 한다. GCE 는 사용하지 않을 때 중지하는 것이 비용을 절약할 수 있는 방법인데 딥러닝 training 이 언제 끝날지 알 수 없기 때문에 인스턴스를 무작정 켜놓을 수밖에 없다. 고사양 시스템으로 설정된 인스턴스를, 그것도 GPU 가 장착된 머신이라면 가격은 생각보다 끔찍할 수 있다. 반면 CloudML 은 인스턴스 없이 t..
 2017 GDG Korea year end party
2017 GDG Korea year end party
한 해 동안의 GDG 생활을 마무리 하는 의미로 구글에서 송년회를 열었다. 참석자는 2017년도 동안 Google 행사에서 발표를 했거나 스탭 활동을 하신 분들, 그리고 GDG 운영진으로 구성되었다. 난 아마도 Google Cloud Platform Korea User Group 운영진 자격으로 초대받은 듯 하다. 나중에 들어보니 GCP 도 GDG 라고 (...) 구글 코리아 22층에 도착하니 이미 파티 준비가 끝나있고 명찰과 추첨 티켓을 부여 받았다. 추첨 티켓은 DevFest 재탕인 듯한. ㅎㅎ 내부는 이미 파티 분위기 물씬. 크리스마스 & 연말 분위기 물씬. 많은 음식과 맥주가 제공 되었는데 평소 구글 식당의 퀄리티에는 많이 못미친다는 평을 들었다. 식당 내부는 생각보다 규모가 작았다. 사실 ..
 withGCP2017 리뷰
withGCP2017 리뷰
Google Cloud Platform (GCP) Users' United Conference 2017 행사가 지난 12월 22일 성황리에 마무리 되었다. IT 콘퍼런스 오거나이저로 참여한 것은 처음이었는데 정말 멋진 경험이 되서 내심 무척 기쁘고 뿌듯하다. 이 감동을 잊혀지기전에 기록으로 남겨두도록 한다. - 매우 짧은 시간동안 이것저것 나름 구색은 다 갖출 수 있었는데 그 이면에는 어떤 행사던지 마찬가지겠지만 각고의 노력을 해준 스탭이 있겠다. 이번 행사도 총 13명의 준비위원회와 3명의 자원봉사자분들이 함께했다. (++1 명의 전폭적인 지원. 마음껏 행사를 준비해보라는 준비위의 어머니) - 준비위 각자 맡은 역할이 있었는데 그 크기에 상관없이 묵묵히 수행하신 분들 정말 대단하다. 오프라..
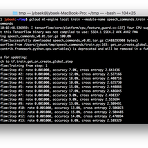 CloudML - 실전 심화
CloudML - 실전 심화
앞서 CloudML 의 개념과 기본적인 사용 방법에 대해서 살펴보았고 이번에는 조금 더 실전에 가까운 글을 발행하도록 한다. 기본편에서 로컬 테스트와 클라우드 테스트를 진행했지만 코드의 내용이 단순히 TensorFlow 의 버전을 확인하는 수준이라서 실전에서 사용하려면 막막하거나 여러 장애 요소가 숨어있다. 이번 글에서는 TensorFlow 홈페이지에 있는 샘플 예제 실습을 통해 CloudML 의 울렁증을 극복할 수 있도록 한다. 예제코드 준비 우선 샘플 예제 사용을 위해 TensorFlow 소스코드를 다운로드 받도록 하자. 다운로드 방법은 무엇이든 상관없고 여기서는 GitHub 을 통해 받는 것으로 한다. 소스코드를 받았으면 이제 샘플 예제를 살펴보아야 하는데 예제에 대한 자세한 설명은 홈페이지를 참고..
 Google Colaboratory를 아시나요?
Google Colaboratory를 아시나요?
Google 에서 또다시 엄청난 것을 일반에 공개했다. 바로 Colaboratory 라는 것인데, Jupyter Notebook 의 협업판 이라고 생각하면 되시겠다. 원래 구글 내부에서 직원들이 사용하던 것인데 이번에 신청만 하면 바로 사용이 가능하게 되었다. (기본 제공은 아직 아닌듯.) 신청하면 1시간 내에 accept 되니 일단 선신청하고 용도는 천천히 생각해보시라. 신청은 아래 URL 에서 진행하면 된다. 신청: https://colab.research.google.com/ 자, 그럼 도대체 Colaboratory 가 무엇인지 조금 더 살펴보도록 하자. Google 에서 기본적으로 제공되는 많은 문서가 있는데 이것들의 장점이라고 하면 로컬 PC 가 아닌 클라우드 환경에서 작업이 되기 때문에 공유가..
 캐글 뽀개기
캐글 뽀개기
캐글(Kaggle)은 2010년 설립된 예측모델 및 분석 대회 플랫폼이다. 기업 및 단체에서 데이터와 해결과제를 등록하면, 데이터 과학자들이 이를 해결하는 모델을 개발하고 경쟁한다. 2017년 3월 구글에 인수되었다. (위키백과) 데이터 분석/엔지니어가 각광받고 머신러닝/딥러닝 기술이 발전함에 따라서 매우 빠른 속도로 성장하고 있는게 바로 캐글 플랫폼이다. 플랫폼 안에는 다양한 데이터가 존재하고 다른 사용자/팀의 코드(커널)와 설명을 확인할 수 있기 때문에 많은 것을 배울 수 있다. 말하자면 개발자가 코드로 이야기 하기 위해서 GitHub 을 사용 하듯이 데이터를 다루는 사람은 캐글로 이야기 한다. 그렇다면 이러한 캐글 플랫폼에는 어떤 것들이 있고 어떻게 사용할 수 있는지 천천히 살펴보도록 하자. htt..
*NIX 머신에 SSH (혹은 Telnet) 로 원격 접속을 하고 프로세스를 백그라운드로 실행하는 경우에 로그아웃(exit)시 실행 됐던 프로세스가 중지 되버리는 현상을 보게 된다. 이는 원격으로 접속한 Shell 이 SSH 연결을 끊는 경우 종료되면서 자식 프로세스에 모두 STOP 시그널을 전송하기 때문인데 이것을 회피하는 몇 가지 방법을 기술한다. 의존 관계 없이 백그라운드로 실행 prog.sh > /dev/null >2&1 & 모든 output 을 생략하고 백그라운드로 실행. 부모와 Shell 과 의존이 없기 때문에 SSH 연결이 종료 되어도 prog.sh 은 계속 실행 상태를 유지한다. nohup nohup prog.sh & 말 그대로 HUP 신호를 무시하는 명령어이다. 보다 자세한 설명은 위키를..
- Total
- Today
- Yesterday