
 오픈소스 오디오 편집툴 : Audacity
오픈소스 오디오 편집툴 : Audacity
대량의 오디오를 편집해야 하는 일이 있어서 막막했는데 Audacity를 만나고 걱정이 해소되었습니다. 여기서 제가 이야기하는 편집이라고 하면 긴 오디오 파일을 여러개로 나눈다던지, 아니면 소리가 없는 구간을 잘라내는 등의 행동을 이야기 합니다. 일단 Audacity는 윈도우와 Mac, 리눅스까지 모든 OS를 지원하는 오픈소스 프로젝트 입니다. 아래 경로에서 다운로드 받으실 수 있습니다. https://www.audacityteam.org/download/ 제 경우에는 ubuntu를 사용하기 때문에 아래와 같이 설치를 진행했습니다. sudo apt-get install audacity 설치가 완료되고 실행하면 아래와 같은 화면을 볼 수 있습니다. 이제 편집하려는 오디오 파일을 끌어다가 중앙에 회색 부분에 ..
python에 librosa를 통해 오디오 파일을 numpy로 읽어오는 코드가 아래와 같이 작성되어 있습니다. import librosa wave_path = '/home/caley/test.wav' sr = 44100 try: wav_np = librosa.core.load(wave_path, sr=sr)[0] except FileNotFoundError as e: print(e) wave_path에 test.wav는 실제로 존재하는 파일이지만 웬일인지 librosa는 에러를 발생시킵니다. FileNotFoundError: [Errno 2] No such file or directory: 'avconv': 'avconv' 이유는 librosa가 내부적으로 사용..
 DataLoader num_workers에 대한 고찰
DataLoader num_workers에 대한 고찰
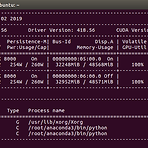
Pytorch에서 학습 데이터를 읽어오는 용도로 사용되는 DataLoader는 torch 라이브러리를 import만 하면 쉽게 사용할 수 있어서 흔히 공식처럼 잘 쓰고 있습니다. 다음과 같이 같이 사용할 수 있겠네요. from torch.utils.data import DataLoader 상세한 설명이 기술되어 있는 공식 문서는 아래 링크에서 살펴볼 수 있습니다. https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader 인자로 여러가지 파라미터를 넘길수 있는데 여기서 이야기하고자 하는 부분은 num_workers인데 공식문서의 설명은 다음과 같이 되어 있습니다. num_workers (int, optional) – how many sub..
 외부 네트워크에서 localhost로 접속 - ngrok
외부 네트워크에서 localhost로 접속 - ngrok
ngrok을 설명하기 전에 이것이 필요한 상황에 대해서 이야기를 간단하게 하는게 이해에 도움이 될 듯 하다. 우리가 웹이나 API를 개발할 때 당장 public 망에서 테스트를 해야 하는 경우를 생각해보자. 예를들어 slack bot을 개발한다고 생각해보면 아래 슬랙 API 화면에 보이는것처럼 public IP를 갖고 있는 서버가 있어야 정상적인 테스트가 가능하다. ( Request URL에 들어가는 주소는 슬랙 API를 처리할 개인 서버쯤으로 생각하면 된다. ) 하지만 개발단계에서 우리는 아직 서버가 없을수도 있고 퍼블릭 IP를 할당받지 못했을 수도 있다. 기타 다른 여러가지 이유로 localhost로 테스트를 해야 하는 경우가 있는데 대부분의 웹 개발는 개발환경이나 프러덕트 환경에 deploy 하기 ..
(*) 우분투 16.0.4 환경에서의 글입니다. 버전이나 OS의 종류에 따라 내용이 적용되지 않을 수도 있습니다. docker를 처음 설치하고 보면 이미지나 컨터이너등 모든 정보가 쌓이는 공간이 /var/lib/docker 로 동작하는 것을 알 수 있습니다. 보통의 사용자 환경을 보면 root 디렉터리는 빠르고 비싼 SSD를 사용하기 때문에 용량이 충분하지 않은데 별 생각없이 이미지와 컨테이너를 생성하다보면 어느샌가 용량부족으로 어려움을 겪게 될 것으로 생각됩니다. 그렇기 때문에 처음 docker를 설치해줬을때부터 이런 데이터가 적재되는 곳을 충분히 여유있는 HDD로 잡아주는게 좋은데요. 이번글에서는 그 방법에 대해서 소개합니다. 우선 데이터 경로가 어디로 잡혀있는지 아래 명령어를 통해 확인해줍니다. $..
nvidia-docker를 사용하기 위해서는 우선 docker가 설치되어 있어야 한다. 우리는 대부분 커뮤니티 버전을 사용하게 될 것이므로 docker Community Edition(docker-ce) 버전으로 설치해주도록 하자. 아래 명령어를 실행하게 되면 get.docker.com에 등록되어 있는 스크립트가 바로 로컬에서 실행되게 되는데 이 스크립트는 기본적으로 docker-ce 레포지토리를 가르키고 있기 때문에 바로 실행시켜주면 되겠다. curl -fsSL https://get.docker.com/ | sudo sh 잠시후 docker 설치가 마무리 되면 nvidia-docker를 설치해주면 된다. 버전이 변경됨에 따라 내용이 달라질 수 있기 때문에 공식 홈페이지의 설치 방법도 함께 확인하면 좋다..
 Next'19 Recap 커뮤니티 라운지 후기
Next'19 Recap 커뮤니티 라운지 후기
코엑스 그랜드볼룸에서 진행된 Next'19 Recap 행사에 다녀왔다. 매년 샌프란시스코에서 연례행사로 진행되는 Cloud Next의 한국버전이라고 생각하면 쉬운데 구글 코리아에서 진행한 행사이다. 내 경우에는 일반적인 컨퍼런스 참여나 오거나이징 하는 것과는 다르게 이번 행사는 커뮤니티라운지를 운영하는 위치로 참여했다. 라운지 안에 모든것은 이미 클라우드팀에서 세팅해줘서 맘편히 놀기만 하면 됐던, 그런 행사가 되시겠다. 함께 운영하신 분들의 이름은 GDG :-) 커뮤니티 라운지의 출입이나 게임 랭크보드 관리, 팝콘, 음료 등 이용하시는 분들에게 필요한 대부분의 편의시설은 라운지 안에 흰색티셔츠를 입고 계신 스태프분들이 도와주셨다. 그럼 GDG는? 라운지를 이용하시는 분들의 네트워킹을 돕거나 기술에 대한 ..
 compare-GPUs for machine learning
compare-GPUs for machine learning
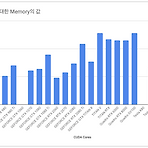
쏟아지는 GPU 속에서 무엇을 선택해야 하는지 고민한 경험은 누구나 있을 듯 합니다. 가격도 만만치 않을 뿐더러 구입했을 때 원하는 목적대로 사용하지 못하면 낭패니까요. 저도 이런 경험이 있습니다. 이런 고민 해소를 위해 벤치마킹 자료까지는 아니더라도 그래픽 카드를 나열해두고 비교할 수 있는 자료가 있었으면 좋겠다고 생각한 적이 있습니다. 그래서 틈틈이 준비해봤죠. 우선 그래픽카드를 선택하는데 가장 큰 부분을 차지하는 CUDA 코어를 비교해봤습니다. (CUDA 코어로 명시한건 현재 NVIDIA 제품만 대상으로 했기 때문입니다) 그래픽카드가 쌍으로(per GPU) 탑재되거나, 세부 모델이 나뉘는 경우는 그래프에는 표기하지 않았습니다. 또한 현재는 NVIDIA제품만 비교했지만 시간 될 때 지속적으로 추가시킬..
 Towards end-to-end speech recognition
Towards end-to-end speech recognition
본 게시물에서 사용된 대부분의 이미지는 아래 링크로부터 첨부되었으며 해당 자료를 통해 많은 영감을 얻었습니다. http://iscslp2018.org/images/T4_Towards%20end-to-end%20speech%20recognition.pdf 하루가 멀다하고 기계가 인간을 뛰어넘는 분야가 늘어나고 있습니다. 구글 딥마인드를 필두로 여러 분야가 정복되고 있는데 2017년 알파고는 절대 정복 할 수 없다고 평가되던 바둑 분야에서 이세돌 9단을 상대로 승리를 거뒀으며 알파스타의 등장으로까지 이어졌습니다. 알파스타는 세계 1위에 프로게이머를 상대로 거둔 승리는 아니었지만 게임 분야에서 충분한 가능성을 보여줬습니다. 아무튼, 여러분야에서 두각을 나타내고 있는 기계학습은 이미지 인식의 경우에는 2015년..
 Google I/O Cloud Hero
Google I/O Cloud Hero
4월에 Next'19 Cloud Hero를 놓쳐서 아쉬워하던차에 5월에 진행된 I/O에도 Cloud Hero 게임이 오픈되었다. 뒤늦게 알아차려서 7일은 넘어갔지만 모든 날짜에 진행되는 게임 내용은 같다. 쉽게 이야기하자면 점수가 각 날자별로 다르게 측정된다고 생각하면 된다. 게임은 전세계에 있는 모든 사람들과 경쟁하는 시스템이고 퀵랩(Qwiklabs)에서 진행된다. 다만 일반적인 링크가 아닌 Cloud Hero 게임을 위한 링크가 제공되고 그 위에서 미션을 진행하는 시스템이 되겠다. 그 미션은 아래와 같다. 총 세 가지 미션이 주어지는데 모두 Google Cloud Platform 위에서 서비스를 만들어가는 것인데 기본적인 것은 GCS(Google Cloud Storage)를 생성하고, 생성한 stor..
 nvidia-docker로 개발환경 한방에 세팅하기
nvidia-docker로 개발환경 한방에 세팅하기
GPU를 사용하는 머신러닝 환경을 구축하기 위해서는 virtualenv, anaconda 등 파이썬의 가상환경을 통한 다양한 방법이 제시되는데 이와 같은 환경에는 문제가 하나 있다. 바로 다양한 버전의 CUDA를 사용하는데 상당히 제한적이라는 것인데, 이게 왜 문제가 되는가 하면 여려가지 전제를 이야기 할 필요가 있다. 보통 다양한 버전의 CUDA를 필요로 하는 경우는 여러개의 프로젝트를 병행으로 개발하는 상태이고 한개의 워크스테이션(혹은 클라우드 인스턴스)에 여러명의 엔지니어가 접속해서 작업을 진행하게 된다. 이때 A라는 엔지니어가 잘못 건드린 글로벌한 CUDA 설정이 B 개발자에게까지 영향을 줄 수 있는 상황이 충분히 존재한다. 이건 혼자 사용하는 머신이라도 마찬가지다. 참담하게도 이런경우에는 시스템..
 한글 자모 분리
한글 자모 분리
한글 자소분리를 처리하기 위해서는 Unicode에 대한 이해가 필요합니다. 우선 위키피디아에 정의되어 있는 한글 음절에 대해 살펴보도록 하시죠. https://ko.wikipedia.org/wiki/한글_음절 우선 여기서 잘 확인하고 넘어가야 하는 부분이 초성, 중성, 종성을 이루는 문자들과 그 개수입니다. 초성 : ㄱㄲㄴㄷㄸㄹㅁㅂㅃㅅㅆㅇㅈㅉㅊㅋㅌㅍㅎ (19개) 중성 : ㅏㅐㅑㅒㅓㅔㅕㅖㅗㅘㅙㅚㅛㅜㅝㅞㅟㅠㅡㅢㅣ (21개) 종성 : ㄱㄲㄳㄴㄵㄶㄷㄹㄺㄻㄼㄽㄾㄿㅀㅁㅂㅄㅅㅆㅇㅈㅊㅋㅌㅍㅎ (28개) 종성의 경우에는 종성이 없는 경우를 위해서 빈 문자도 포함해서 28로 취급합니다. 예를들면 "가", "우", "소" 등이 종성이 없는 경우가 있겠죠. 또한 위 링크에서 확인한 한글문자코드의 범위는 0xAC00(가) ~ ..
- Total
- Today
- Yesterday