
티스토리 뷰
본 게시물에서 사용된 대부분의 이미지는 아래 링크로부터 첨부되었으며 해당 자료를 통해 많은 영감을 얻었습니다.
http://iscslp2018.org/images/T4_Towards%20end-to-end%20speech%20recognition.pdf
하루가 멀다하고 기계가 인간을 뛰어넘는 분야가 늘어나고 있습니다. 구글 딥마인드를 필두로 여러 분야가 정복되고 있는데 2017년 알파고는 절대 정복 할 수 없다고 평가되던 바둑 분야에서 이세돌 9단을 상대로 승리를 거뒀으며 알파스타의 등장으로까지 이어졌습니다. 알파스타는 세계 1위에 프로게이머를 상대로 거둔 승리는 아니었지만 게임 분야에서 충분한 가능성을 보여줬습니다. 아무튼, 여러분야에서 두각을 나타내고 있는 기계학습은 이미지 인식의 경우에는 2015년에 이미 인간과 동등한 수준이 되었다고 이야기되고 있습니다.

하지만 기계학습을 통해 아직까지 제대로 된 서비스가 없는 블루오션이 있으니 바로 음성인식(Speech recognition) 분야라고 생각됩니다. 물론 음성합성(speech synthesis)처럼 Text를 발화시키는 것은 상당한 수준까지 올라왔다고 말할 수 있지만 말이죠. 합성이 이렇게 성공적은 결과를 가져온 기반에는 Google의 Tacotron2가 있습니다. 클로바는 유인나 목소리를 내고 이병헌 목소리의 네오사피엔스는 이제 더 이상 우리에게 음성합성이 먼 나라 이야기가 아님을 잘 보여주고 있습니다. 특히 최근에는 sung kim 교수님이 컨퍼런스에서 초반 수분을 본인의 목소리를 음성합성한 오디오 파일을 재생해두고 립싱크로 세션을 진행했는데 눈치챈 사람이 없었다는 후문도 있습니다. 다음 링크를 통해 이런 기술의 근간이 되는 tacotron2의 결과를 살펴볼 수 있습니다. : https://google.github.io/tacotron/publications/tacotron2/index.html

그렇다면 음성인식은 어째서 합성과는 다르게 제대로 정복되지 않은걸까요? 아직은 갈 길이 멉니다. 일단 인식은 여러 논문에서 LibriSpeech나 WSJ, TIMIT등의 데이터를 기반으로 SOTA(state of the art)를 주장하지만 이건 단순히 모델을 평가하기 위한 잣대일뿐이지 실제 서비스를 논할 수 있는 지표는 아닙니다. 말하자면 최고의 퍼포먼스를 내기위해 다른 무언가를 포기하는 그런 모양새인데, "간지를 위해 시야를 포기했어!" 같은 만화 대사가 생각나죠.
대부분 서비스에 적합한 모델로는 SOTA를 찍는게 쉽지 않습니다. 실제로 페이퍼등을 통해 공개조차 된 사례가 없으니까요. 또한 실제 서비스화 시키기 위해서는 대부분의 분야에 end-to-end 시스템이 고려되어야 하는데 이게 가능하기 위해서는 microphone의 구조적인 문제 등으로 삽입되는 noise에 대한 suppression이 기본적으로 제공되어야 하며 화자 구분이나 음성 추출까지 "정확하게" 가능해야 합니다. 더욱이 각 국가에 존재하는 지역적인 방언이나 특유의 억양까지 정복해야 합니다. 그러기 위해서는 언어모델 등의 후처리를 위한 기법이나 다른 여러가지 방법이 고안되어야겠죠. "물냉면"을 주문 시켰는데 "밀냉면"이 도착한다면 황당하지 않을까요? 어쩌면 극단적인 예로 보이고 서비스를 위해서 주문내역을 사용자 확인에게 다시 확인하는 등은 고민할 수 있겠지만 아무튼 음성을 통한 서비스에서 정확도는 이렇듯 상당히 중요합니다. 그럼 과거부터 현재까지 어떻게 인식분야가 진행되고 있는지 살펴보도록 하겠습니다.
What is End-to-End ASR?
End-to-End ASR(Automatic Speech Recognition)은 입력되는 음성을 받아서 처리하고 최종적으로는 이를 문자로 표현하는 것을 나타냅니다. 이런 프로세스를 구축하기 위해서는 통상 아래와 같은 pipeline을 사용하게 됩니다.

입력되는 음성의 특징을 추출하고 Acoustic model을 통하고 decoder에서 언어모델 등이 후처리를 진행합니다. 이런 pipeline을 기반으로 End-to-End ASR을 서비스하기 위해 여러가지 방식이 제시되었고 여기서 하나씩 살펴보도록 합니다. 제일 먼저 등장하는건 [Graves et al., 2006]이 제안한 CTC(Connectionist Temporal Classification)모델 입니다.

오래된만큼 상당히 유명한 모델이죠. CTC 컨셉은 간단합니다.

[Uni | Bi]directional RNN(혹은 LSTM)을 여러층 쌓고 인코더로 들어오는 입력 데이터는 최종적으로 Softmax를 통과해서 출력됩니다. 이런 CTC를 기반으로 End-to-End ASR을 [Graves and Jaitly, 2014]이 제안했습니다. 이때 Graves는 Google DeepMind 소속이었네요.

이 논문에서는 character-based CTC를 사용해서 단어를 추론하고 더 좋은 성능을 내기 위해서 후처리로 언어모델이 사용합니다. 이런 character-based CTC를 사용하는 대표적인게 바이두의 deepspeech2가 되겠습니다.
한편 비슷한 시기에 Listen, Attend and Spell(LAS) 모델이 Google Brain에서 제안됩니다. 이후부터 ASR은 CTC와 LAS로 나뉜다고 봐도 무방할 정도로 너무나 유명한 모델이죠.

LAS의 개념은 아래 그림에서 잘 표현되고 있습니다. Listener, Attention, 그리고 Speller로 나눠지는 부분에 주목하면 됩니다.
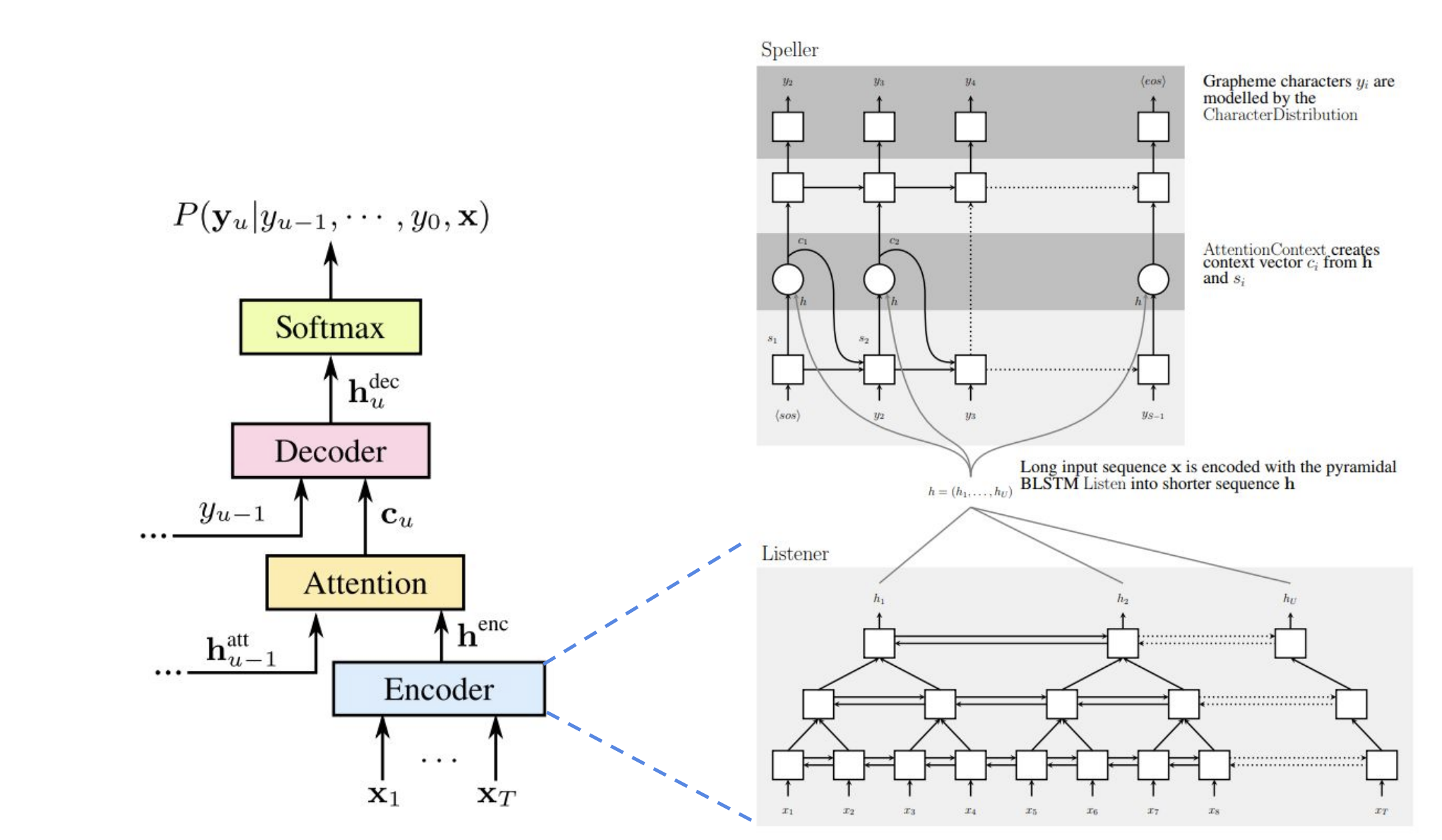
Listener는 피라미드 형식으로 구성된 bidirectional LSTM(BLSTM) 인코더이며 입력 시퀀스 x로부터 특징을 뽑아냅니다. Speller는 attention-based 디코더에서 h와 s로부터 컨텍스트 벡터 c를 생성하고 이를 기반으로 Grapheme 캐릭터 y를 뽑아냅니다. 이런 과정에서 <sos>와 <eos>를 특별한 토큰으로 사용하는데 각각 special start-of-sentence, end-of-sentence를 나타냅니다.
CTC와 LAS는 요즘 논문에서도 자주 인용될 정도로 인기가 있는 모델이지만 이 자체만으로는 Streaming에 적합하지 않습니다. 전체 sentence를 입력으로 넣고 처리하다보니 여러가지 문제가 발생한것이죠. 이를 보안하기위해 Online 모델이 등장하게 됩니다.
Online Models
Online Model은 streaming 음성을 처리할 수 있도록 구조적으로 설계된 모델인데 대표적으로 RNN-Transducer, NT, MoChA가 있겠습니다. 특히 RNN-Transducer의 경우에는 구글의 STREAMING END-TO-END SPEECH RECOGNITION FOR MOBILE DEVICES로 다시한번 주목받게 되었습니다.
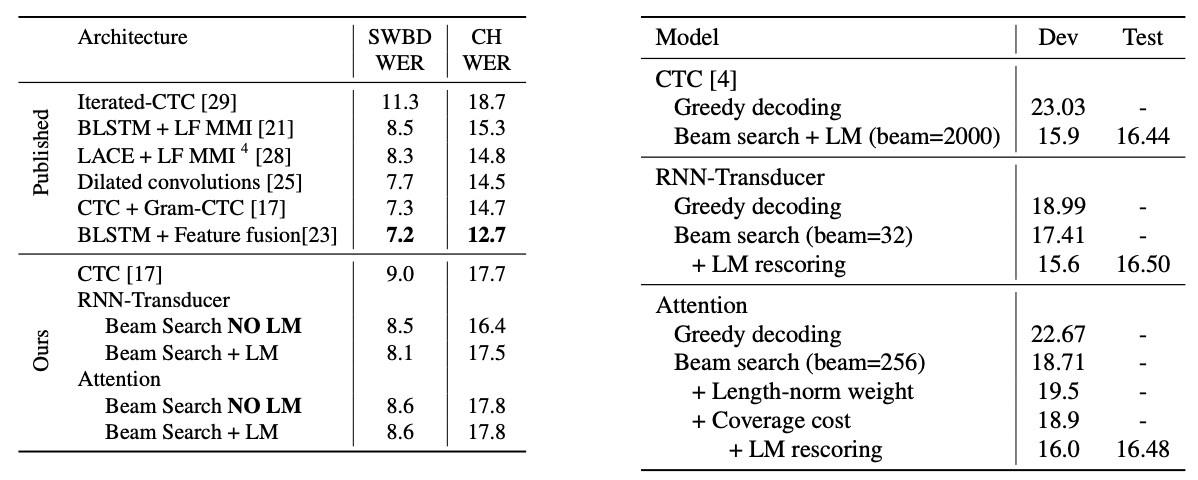
재밌는건 CTC-based를 제안했던 저자들이 Online Models을 새롭게 제시하고 있다는 사실입니다. Graves는 RNN-Transducer를, Jaitly는 NT를 각각 제안했네요. 아래 바이두에서 내놓은 자료에 따르면 CTC나 LAS 모델과 비교해서 RNN-Transducer의 인식률이 결코 밀리지 않는다는 주장을 하고 있습니다. 아직 명확하게 동일한 데이터를 기준으로 SOTA를 증명해낸 내용은 찾기 어렵지만요. (동일한 데이터 기준 : 예를들면 LibriSpeech나 WSJ같은)
아무튼, Online models중에 대표되는 RNN-T를 살펴보면 아래 그림에서 그 개념을 잘 보여주고 있습니다. 기존 CTC 모델과의 차이를 보여주는 그림인데, Encoder에 Prediction Network를 연결해서 사용합니다. prediction network를 연결시켜줌으로써 후처리 언어모델의 효과를 얻을 수 있습니다.

이후에도 CTC나 LAS의 변형과 새로운 모델이 쏟아지고 있지만 명확히 SOTA를 증명해낸 페이퍼는 찾기 어렵습니다. 막연하게 "인식률은 기존과 유사하게 나왔으며 inference속도는 더욱 빨라졌다." 혹은 "전체적으로 약간 더 좋아졌다." 처럼 표현됩니다. 앞에서부터 계속 페이퍼에는 그들의 주장을 뒷받침하는 근거가 없다는데 초점을 맞추고 있는데 Linus Torvalds의 말을 인용합니다. 제가 참 좋아하는 말인데요, 결국은 "말이 쉽지 증명해내라" 이겁니다. 성공적인 결과를 냈으면 모두가 공감할 수 있는 오픈데이터를 기반으로 SOTA를 증명해봐라 이거죠.
Talk is cheap. Show me the code.자, 아무튼 이렇게 쏟아지는 논문들을 살펴보고 있자면 현대에 와서는 기존에 제시된 모델의 hierarchies에 변화를 주거나 새롭게 제안되는 기법들(예를들면 SpecAugment)을 잘 연동해서 사용할 수 있는 technical한 능력도 필요하겠습니다. 그러기 위해서는 기존 모델들을 이해하고 새로운 것과 연동 시킬 수 있는 언어적인 스킬도 필요하겠네요.
Future
당장 내일 일도 알 수 없지만 음성합성과 인식률이 100%에 근접해졌을 때 미래에 어떤일이 벌어질지 조심스럽게 생각해봅시다. 목소리로 할 수 있는 모든 직업이 사라질겁니다. 대표적으로는 성우, 상담원 심지어는 통역을 통한 목소리에도 영향을 줄겁니다. 이 모든게 대단한 음성 장비가 필요한것도 아니고 우리 손 끝의 on-device에서 가능하다는거죠.

인식과 합성의 큰 파도가 출렁이는 지금 시점에야 독특한 목소리를 판매하는 것이 가능할겁니다. 우리의 주민등록번호가 중국에서 수백원 정도밖에 안된다는 이야기를 들었던 것 같은데요. 우리 목소리도 그렇게 될 날이 올거라고 예상됩니다. 한편 기술 발전에 따라 혜택받는 곳도 많을겁니다. 많은 사람들이 감정노동으로부터 해방될 것이고 장애를 갖고 있는 사람들에게는 기술이 곧 빛이 되겠죠. 빨리 그런 세상이 왔으면 좋겠습니다. 제가 할 수 있는 부분에는 부지런히 기여 할 생각입니다.
'개발 > 기계학습' 카테고리의 다른 글
| DataLoader num_workers에 대한 고찰 (8) | 2019.05.28 |
|---|---|
| compare-GPUs for machine learning (0) | 2019.05.14 |
| ImportError: numpy.core.xxx failed to import (2) | 2019.04.19 |
| Usage TPU in Google Colaboratory (1) | 2019.04.03 |
| Use multiple versions of CUDA (0) | 2019.03.11 |
- Total
- Today
- Yesterday