
티스토리 뷰
GPU를 사용하는 머신러닝 환경을 구축하기 위해서는 virtualenv, anaconda 등 파이썬의 가상환경을 통한 다양한 방법이 제시되는데 이와 같은 환경에는 문제가 하나 있다. 바로 다양한 버전의 CUDA를 사용하는데 상당히 제한적이라는 것인데, 이게 왜 문제가 되는가 하면 여려가지 전제를 이야기 할 필요가 있다. 보통 다양한 버전의 CUDA를 필요로 하는 경우는 여러개의 프로젝트를 병행으로 개발하는 상태이고 한개의 워크스테이션(혹은 클라우드 인스턴스)에 여러명의 엔지니어가 접속해서 작업을 진행하게 된다. 이때 A라는 엔지니어가 잘못 건드린 글로벌한 CUDA 설정이 B 개발자에게까지 영향을 줄 수 있는 상황이 충분히 존재한다. 이건 혼자 사용하는 머신이라도 마찬가지다.
참담하게도 이런경우에는 시스템에 전체적으로 CUDA 설치를 다시해주거나 꼬여버린 PATH를 다시 잡아주는 등 여러 사람이 고통을 분담해서 겪게된다. 정말이다. 심한경우에는 다양하게 설치되어 있는 CUDA를 모조리 새로 설치해야 할 수도 있다.
서론이 조금 길었는데 여기서는 GPU 개발환경을 파이썬의 가상환경이 아닌 도커로 그 해답을 제시하고자 한다.
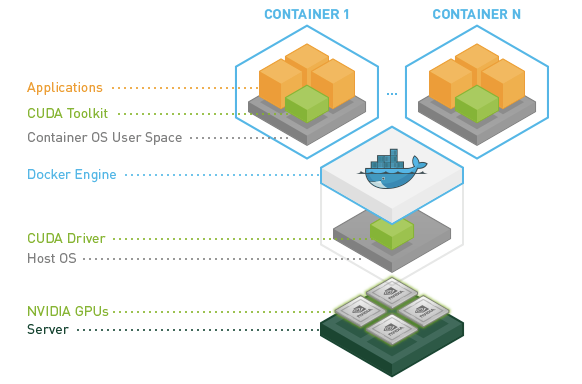
우선 nvidia-docker를 사용할 수 있다는 전제하에 이야기하도록 한다. 우리가 흔히 아는 docker 명령처럼 다음과 같이 컨테이너를 생성 해보자. 이때 base image(nvidia/cuda:10.0-base)는 현재 로컬에 존재하지 않기 때문에 최초에는 서버에서 다운로드 받아지게 된다.
nvidia-docker run -d --shm-size 2G -it --name <CONTAINER_NAME> \
nvidia/cuda:10.0-base /bin/bash여기서는 두 가지만 알면 되는데 첫 번째로 cuda:10.0 뒤에 붙은 base의 의미다. base 이외에도 아래와 같이 runtime, devel을 사용할 수 있는데 단순하게 CUDA만 사용하는 프로젝트라면 base로도 충분하지만 CUDA에 존재하는 라이브러리를 사용한다거나 header 파일을 참조해서 뭔가 컴파일해야 하는 프로젝트의 경우에는 runtime, devel이 각각 필요할 수 있겠다. 무조건 devel로 하면 속편한거 아닌가? 라고 할 수 있겠지만 그 용량 차이를 무시할 수 없다. base 이미지의 경우에는 135MB, devel의 경우에는 2.36GB이니 약 20배 가까운 차이를 나타내기 때문이다. (사실 이미지를 통해 만들어지는 컨테이너들의 용량 문제가 제일 심각하다)

두 번째로는 --shm-size인데, 생성되는 이미지를 사용하는 컨테이너에서 사용하게 되는 shared memory 공간이다. 머신러닝에서 이 영역이 충분하지 못하면 여러가지 에러를 만날 수 있기 때문에 적당한 크기로 설정이 필요하다. 일반적으로 도커환경이 아닌 우리 시스템의 경우 /dev/shm은 tmpfs라는 이름으로 수십 GB까지 할당이 되니 든든하게 챙기면 되겠다.
이미지 다운로드가 끝나면 docker images 명령어로 아래와 같이 다운로드 된 이미지 확인이 가능하다.
$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
nvidia/cuda 10.0-devel 30648438f8b8 4 weeks ago 2.36GB
nvidia/cuda 10.0-base a55b7fc6f6a0 4 weeks ago 135MB그리고 해당 이미지를 통해 생성된 컨테이너는 docker ps 를 통해 확인된다.
$ docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
395d76bfc213 nvidia/cuda:10.0-devel "/bin/bash" 27 hours ago Up 27 hours test1
78db93f63ec3 nvidia/cuda:10.0-base "/bin/bash" 3 weeks ago Exited (0) 3 weeks ago test2정상적으로 cuda:10.0-base를 다운로드 받고 컨테이너가 생성되었으면 이제 컨테이너에 접속해서 필요한 기본 패키지를 설치해주면 되겠다. 여기서 이야기하는 기본패키지는 우리가 프로젝트를 진행하기 위해서 필요한 최소한의 것들이 되겠다. 예를들면 그게 git 일수도 있고, vim일수도 있고. 일단 현재 상태는 컨테이너가 시작(start)되어 있는 상태인데 그렇지 않다면 start 시켜주도록 하자. 자, 아래와 같이 컨테이너에 접속을 하고,
docker exec -it <CONTAINER_NAME> bash다음과 같이 기본적으로 필요한 패키지를 다운로드 받을 수 있도록 sources.list를 세팅을 해준다.
sed -i 's/archive.ubuntu.com/ftp.daumkakao.com/g' /etc/apt/sources.list
apt-get update
apt-get dist-upgrade -y
세팅이 끝났으면 필수 패키지를 설치해주도록 한다. 개인적으로 생각하는 필수 패키지 목록이니 각자의 환경에 맞도록 변경해주면 되겠다.
apt-get install -y wget vim git gcc build-essential현재 컨테이너에는 python3이 설치되지 않은 상태인데 필요하다면 conda로 잡아주는게 여러모로 편하다. 굳이 python3를 기본으로 사용하겠다고 alias를 잡아주는 등의 액션이 취해졌을 때 어느순간 발생하는 side-effect로 고통받지 않으려면.. 아래와 같이 conda3을 다운로드 받고 설치해주도록 한다.
wget https://repo.anaconda.com/archive/Anaconda3-2019.03-Linux-x86_64.sh
bash Anaconda3-2019.03-Linux-x86_64.sh자, 이제 개인적으로 생각하는 공통 환경 세팅이 끝났다. 본인의 프로젝트에 맞는 머신러닝 프레임워크를 설치해서 막힘없이 개발하실 수 있기를 바란다. :-)
'개발 > docker' 카테고리의 다른 글
| docker 데이터 디렉터리 변경 (14) | 2019.05.27 |
|---|---|
| nvidia-docker Installation in Ubuntu (2) | 2019.05.27 |
| RuntimeError: DataLoader worker (pid 13881) is killed by signal: Bus error. (10) | 2019.04.15 |
| 이미지, 컨테이너 export, import (0) | 2016.12.12 |
| 네트워크 관리 (0) | 2016.12.01 |
- Total
- Today
- Yesterday