
티스토리 뷰
Colab의 사용권한을 신청하고 accept 되어야만 사용할 수 있었던 시절이 있었는데 이제는 너무나 보편화 되었고 K80 GPU는 물론 TPU까지 마음껏 굴려볼 수 있는 상태가 되었습니다. 참고글: Google Colaboratory를 아시나요?
하지만 막상 찾아보면 TPU 사용예제가 많이 안보이는데 TensorFlow 공식 예제가 너무 잘되어 있기 때문일까요? 아무튼 한글 자료는 턱없이 부족한데 도움이 될 누군가를 위해 메모로 남겨두도록 합니다. 이 글은 tf 1.13 버전을 기반으로 하고 있기 때문에 keras가 공식적으로 tensorflow 안에 모듈로 자리 잡고 있는 상태입니다. 다음은 TensorFlow 공식 홈페이지에 있는 MNIST 예제코드입니다.
import tensorflow as tf
mnist = tf.keras.datasets.mnist
(x_train, y_train),(x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(512, activation=tf.nn.relu),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=5)
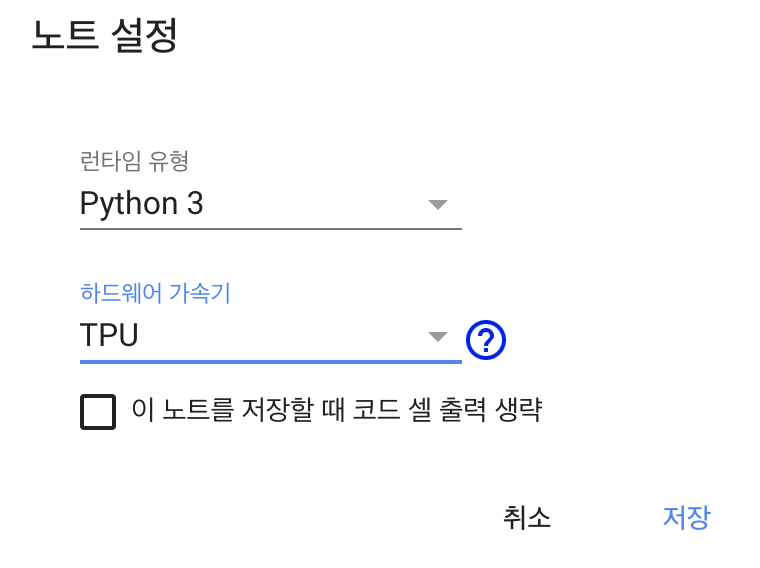
model.evaluate(x_test, y_test)이 예제를 Colaboratory에서 TPU를 사용해서 돌려볼텐데 우선 Colab의 런타임 환경을 TPU로 변경해줘야합니다. 상단 메뉴바에서 [런타임 -> 런타임 설정]을 찾아서 클릭하도록 합니다.

이후 출력되는 팝업에서 하드웨어 가속기를 TPU로 설정해줍니다.
이제 준비가 끝났으니 코드를 약간 수정해주도록 합니다. keras 의 경우에 하드웨어에 GPU 존재 유무에 따라서 자동으로 하드웨어 가속기를 잡아주지만 TPU 같은 경우에는 별도로 잡아줘야 하는 사소한 불편함이 있습니다. 무슨이야기인지 모르시는 분들을 위해 조금 더 부연설명을 하자면 위에 MNIST 예제 코드가 GPU가 없는 환경에서는 CPU로 모델 학습이 진행되고, GPU가 있는 환경에서는 GPU를 이용해서 학습을 진행된다는 이야기 입니다. 아무튼 TPU 사용을 위해 소스코드 일부를 수정해야 하는건 그 강력함에 비하면 소소하겠죠.
일단 위에서 tf.keras.models.Sequential 로 생성한 model 을 tpu 모델로 변경해줘야 합니다. 아래처럼 말이죠.
import os
tpu_model = tf.contrib.tpu.keras_to_tpu_model(
model,
strategy=tf.contrib.tpu.TPUDistributionStrategy(
tf.contrib.cluster_resolver.TPUClusterResolver(tpu='grpc://' + os.environ['COLAB_TPU_ADDR'])
)
)위에 코드는 그대로 복사 붙여넣기해서 사용해도 됩니다. model 이라는 변수 이름만 유효하다면요. 그리고 그 다음에는 학습과 평가를 위한 model.fit(), model.evaluate() 도 위에서 변경해준 tpu_model 을 사용하도록 변경해줍니다. 정말 다른 부분은 아무것도 수정하지 않고 model -> tpu_model 로 다시 잡아줬을 뿐입니다.
tpu_model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
tpu_model.fit(x_train, y_train, epochs=5)
tpu_model.evaluate(x_test, y_test)이제 모델을 돌려볼까요?
WARNING: The TensorFlow contrib module will not be included in TensorFlow 2.0.
For more information, please see:
* https://github.com/tensorflow/community/blob/master/rfcs/20180907-contrib-sunset.md
* https://github.com/tensorflow/addons
If you depend on functionality not listed there, please file an issue.
INFO:tensorflow:Querying Tensorflow master (grpc://10.46.73.154:8470) for TPU system metadata.
INFO:tensorflow:Found TPU system:
INFO:tensorflow:*** Num TPU Cores: 8
INFO:tensorflow:*** Num TPU Workers: 1
INFO:tensorflow:*** Num TPU Cores Per Worker: 8
INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:CPU:0, CPU, -1, 4055455857912207420)
INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:XLA_CPU:0, XLA_CPU, 17179869184, 3842762595509406304)
INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:0, TPU, 17179869184, 5241287887114469441)
INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:1, TPU, 17179869184, 12764949589812289195)
INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:2, TPU, 17179869184, 1400418604524209240)
INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:3, TPU, 17179869184, 9299367928412358572)
INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:4, TPU, 17179869184, 4679910220033700852)
INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:5, TPU, 17179869184, 12582914926270259941)
INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:6, TPU, 17179869184, 9862471167866310413)
INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:7, TPU, 17179869184, 18013826450553126883)
INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU_SYSTEM:0, TPU_SYSTEM, 17179869184, 4154843896672514673)
WARNING:tensorflow:tpu_model (from tensorflow.contrib.tpu.python.tpu.keras_support) is experimental and may change or be removed at any time, and without warning.
Epoch 1/5
INFO:tensorflow:New input shapes; (re-)compiling: mode=train (# of cores 8), [TensorSpec(shape=(4,), dtype=tf.int32, name='core_id0'), TensorSpec(shape=(4, 28, 28), dtype=tf.float32, name='flatten_input_10'), TensorSpec(shape=(4, 1), dtype=tf.int32, name='dense_1_target_10')]
INFO:tensorflow:Overriding default placeholder.
INFO:tensorflow:Cloning Adam {'lr': 0.0010000000474974513, 'beta_1': 0.8999999761581421, 'beta_2': 0.9990000128746033, 'decay': 0.0, 'epsilon': 1e-07, 'amsgrad': False}
INFO:tensorflow:Remapping placeholder for flatten_input
WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/contrib/tpu/python/tpu/keras_support.py:302: to_float (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.cast instead.
INFO:tensorflow:KerasCrossShard: <tensorflow.python.keras.optimizers.Adam object at 0x7f41cce154a8> []
INFO:tensorflow:Started compiling
INFO:tensorflow:Finished compiling. Time elapsed: 1.2388334274291992 secs
INFO:tensorflow:Setting weights on TPU model.
INFO:tensorflow:CPU -> TPU lr: 0.0010000000474974513 {0.001}
INFO:tensorflow:CPU -> TPU beta_1: 0.8999999761581421 {0.9}
INFO:tensorflow:CPU -> TPU beta_2: 0.9990000128746033 {0.999}
INFO:tensorflow:CPU -> TPU decay: 0.0 {0.0}
WARNING:tensorflow:Cannot update non-variable config: epsilon
WARNING:tensorflow:Cannot update non-variable config: amsgrad
60000/60000 [==============================] - 22s 374us/sample - loss: 0.2207 - acc: 0.9344
Epoch 2/5
60000/60000 [==============================] - 18s 299us/sample - loss: 0.0972 - acc: 0.9702
Epoch 3/5
60000/60000 [==============================] - 18s 308us/sample - loss: 0.0686 - acc: 0.9781
Epoch 4/5
60000/60000 [==============================] - 19s 309us/sample - loss: 0.0541 - acc: 0.9824
Epoch 5/5
60000/60000 [==============================] - 19s 314us/sample - loss: 0.0420 - acc: 0.9864
INFO:tensorflow:New input shapes; (re-)compiling: mode=eval (# of cores 8), [TensorSpec(shape=(4,), dtype=tf.int32, name='core_id_10'), TensorSpec(shape=(4, 28, 28), dtype=tf.float32, name='flatten_input_10'), TensorSpec(shape=(4, 1), dtype=tf.int32, name='dense_1_target_10')]
INFO:tensorflow:Overriding default placeholder.
INFO:tensorflow:Cloning Adam {'lr': 0.0010000000474974513, 'beta_1': 0.8999999761581421, 'beta_2': 0.9990000128746033, 'decay': 0.0, 'epsilon': 1e-07, 'amsgrad': False}
INFO:tensorflow:Remapping placeholder for flatten_input
INFO:tensorflow:KerasCrossShard: <tensorflow.python.keras.optimizers.Adam object at 0x7f41cce5b390> []
INFO:tensorflow:Started compiling
INFO:tensorflow:Finished compiling. Time elapsed: 0.5766003131866455 secs
9952/10000 [============================>.] - ETA: 0s - loss: 0.0649 - acc: 0.9808INFO:tensorflow:New input shapes; (re-)compiling: mode=eval (# of cores 8), [TensorSpec(shape=(2,), dtype=tf.int32, name='core_id_10'), TensorSpec(shape=(2, 28, 28), dtype=tf.float32, name='flatten_input_10'), TensorSpec(shape=(2, 1), dtype=tf.int32, name='dense_1_target_10')]
INFO:tensorflow:Overriding default placeholder.
INFO:tensorflow:Remapping placeholder for flatten_input
INFO:tensorflow:KerasCrossShard: <tensorflow.python.keras.optimizers.Adam object at 0x7f41cce5b390> []
INFO:tensorflow:Started compiling
INFO:tensorflow:Finished compiling. Time elapsed: 0.41895103454589844 secs
10000/10000 [==============================] - 4s 411us/sample - loss: 0.0646 - acc: 0.9809
[0.06464320362857542, 0.9809]TF2.0 에서는 contrib 모듈이 탑재되지 않을 예정이라고 하네요. 지금 당장은 아무 문제가 없죠. worker 1개가 동작하고 있고 안에서 9개의 TPU Core가 돌고 있습니다. 어마어마하지만 사실 위의 예제에서는 빛을 보지 못합니다. 대략 epoch당 18-22초 정도 걸렸는데 Colab GPU(k80)의 경우 8-9초 안에 끝냅니다. 더 슬픈건 CPU의 경우에는 16초에 끝나네요. 오히려 TPU처리가 느린건 병렬처리 연산에 드는 비용이 MNIST의 행렬연산에 드는 비용보다 더 비싸기 때문인데 이 부분에 대한 언급은 글의 의도와 맞지 않기 때문에 넘어가도록 하겠습니다.
자, 이걸로 Colab에서 TPU 사용해보는 예제는 끝입니다. 정말 심플하죠? 혹시라도 요즘 Colab에 TPU가 핫하다는데 덜컥 사용해보지 못하고 계셨던 분들이 있었다면 도움이 되셨기를 바랍니다. :-)
'개발 > 기계학습' 카테고리의 다른 글
| Towards end-to-end speech recognition (3) | 2019.05.10 |
|---|---|
| ImportError: numpy.core.xxx failed to import (2) | 2019.04.19 |
| Use multiple versions of CUDA (0) | 2019.03.11 |
| ImportError: libcudnn.so.7: cannot open shared object file: No such file or directory (2) | 2019.03.11 |
| [Kaldi] voxforge online demo (9) | 2019.03.05 |
- Total
- Today
- Yesterday